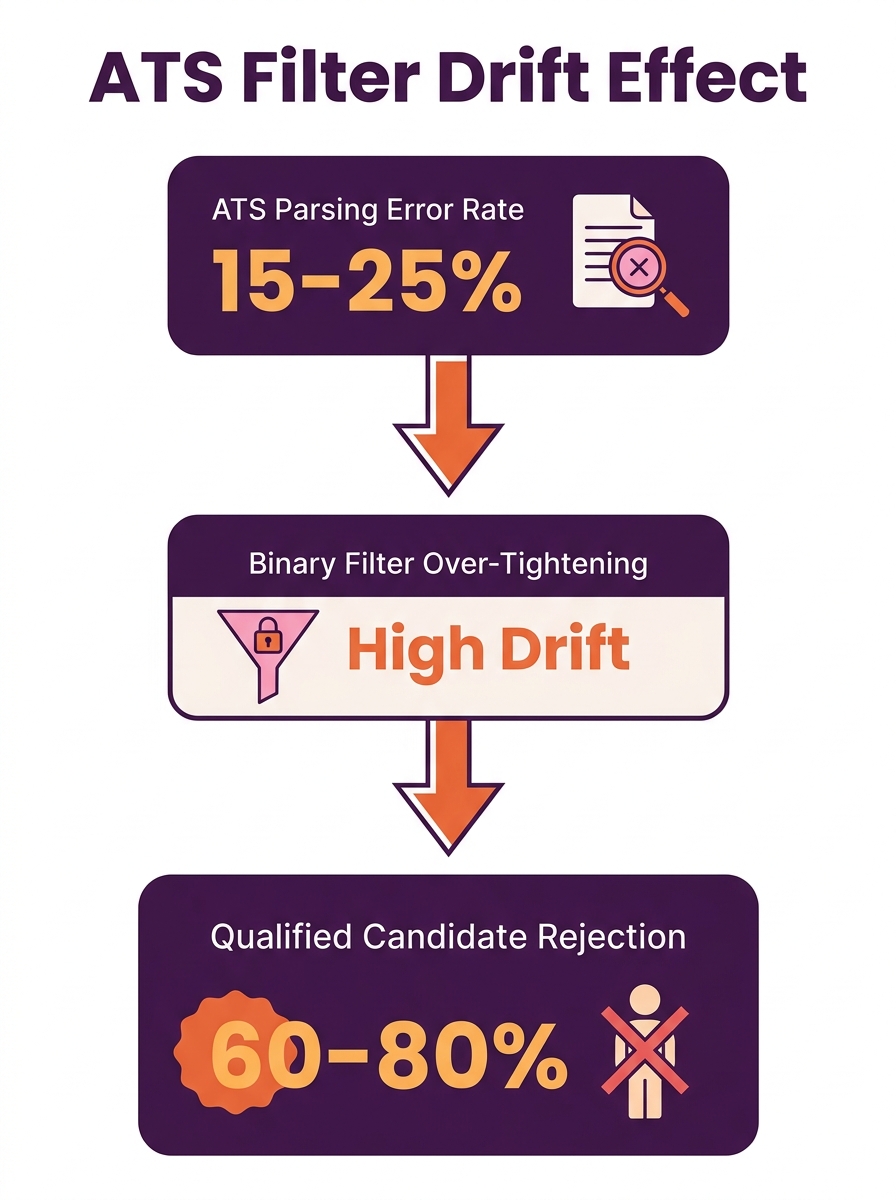
AI-driven skill extraction in modern ATS platforms carries a 15–25% error rate, according to current parsing benchmarks. That error rate, compounded across the 182% application volume increase documented between 2021 and Q3 2024, means even carefully configured intake filters are silently discarding qualified candidates at scale.
TL;DR: Switching from binary knockout filters to weighted scoring tiers with monthly rejection audits reduces false-negative candidate loss by 30–40%. Most recruiting teams never check what their ATS actually rejects. The fix starts with reviewing 25–30 declined applications each month and mapping synonym gaps in job descriptions.
The Compound Error Behind Filter Drift
Intake filters don’t fail all at once. They drift. Each small adjustment (a new knockout question here, a tighter experience threshold there) compounds the 15–25% baseline parsing error into something much larger. Across high-volume roles processing hundreds of applications per week, even a 5% false-negative increase translates to dozens of qualified candidates rejected before any human reviews them.
The scale of the problem becomes clear when you look at volume trends. Application volumes to open roles surged 182% between 2021 and Q3 2024, according to analysis of ATS intake data. Recruiting teams responded by cranking up their filters. And 88% of employers now acknowledge their systems screen out qualified candidates before a recruiter ever sees them.
That 88% figure deserves scrutiny. It doesn’t mean 88% of employers are bad at filtering. It means nearly nine out of ten have never validated their filter configurations against actual candidate quality data. The diagnostic signal, as documented in application volume management research, is an application-to-phone-screen conversion rate below 10%. If your ratio sits there, your filters have overshot.
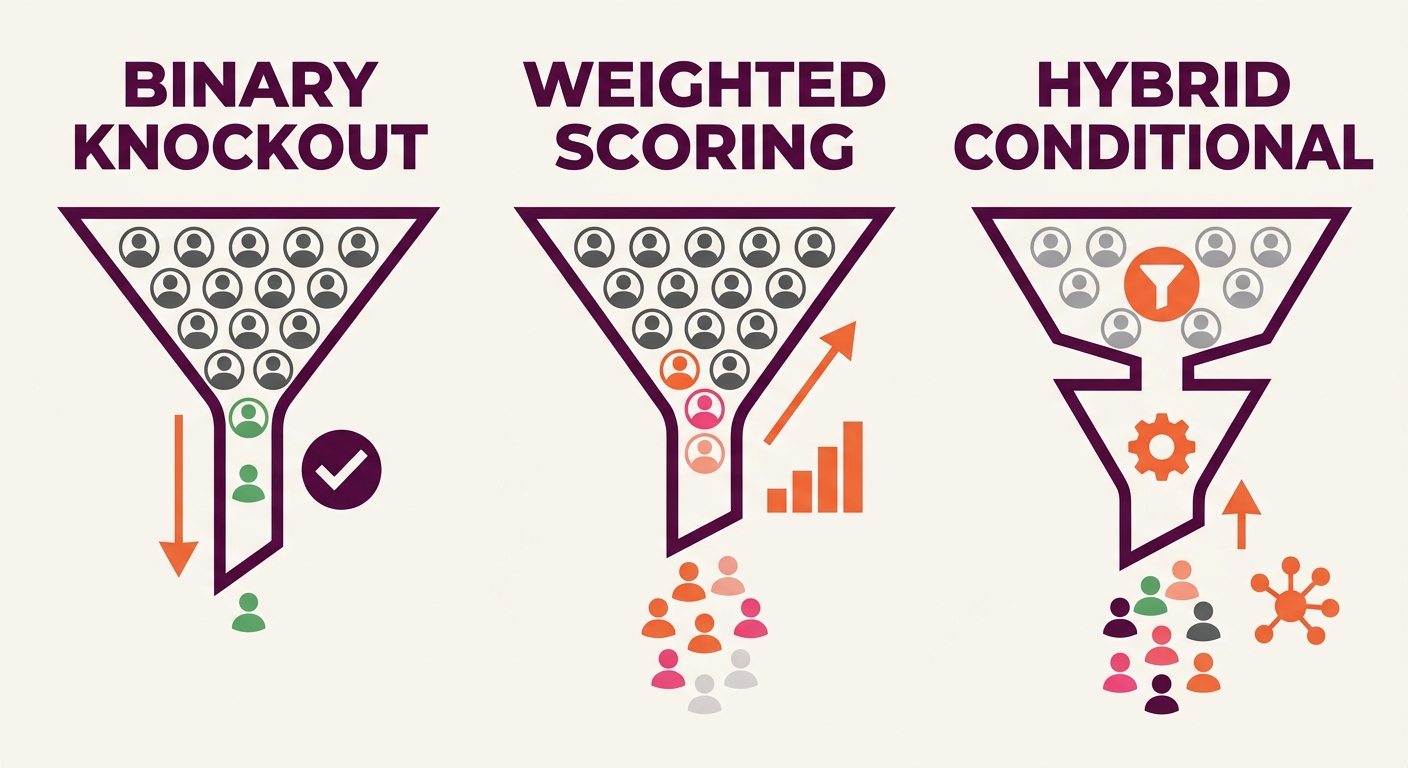
Three Filtering Models and What Each One Actually Costs
The filtering model you run determines whether you lose 20% of good applicants or 50%. Most teams never make this choice deliberately. The default settings ship with the platform, someone adds a few knockout questions during implementation, and the system runs for months without anyone checking what it’s rejecting.
Here’s how the three common configurations compare across key recruitment metrics 2026 teams should track:
| Filtering Model | Typical False-Negative Rate | Candidate Abandonment Impact | Recruiter Review Load | Best Fit |
|---|---|---|---|---|
| Binary Knockout | 40–50% of qualified candidates rejected | High (rigid questions deter applicants) | Low (few pass through) | Only for hard compliance requirements |
| Weighted Scoring Tiers | 15–20% of qualified candidates missed | Moderate | Moderate (tiered review) | Mid-to-high volume roles |
| Hybrid Conditional | 10–15% of qualified candidates missed | Low (30–40% less abandonment) | Higher but targeted | High-volume hiring strategies requiring quality |
Binary knockout gates are the bluntest instrument in ATS intake filtering. A rigid “must have 5+ years experience” gate will reject a career changer with 3 years of directly relevant work plus transferable skills from an adjacent field. Weighted scoring tiers assign points across multiple criteria and rank candidates rather than eliminating them. Hybrid conditional models combine minimal binary gates (reserved for genuine legal or safety requirements) with tiered scoring and short conditional assessments.
The hybrid approach aligns with a broader industry shift documented in Bullhorn’s 2026 ATS Usage Report. GRID research cited in that report found AI could free 3.6 hours per week on screening and admin tasks alone. But those time savings evaporate when filters are so tight that recruiters spend their freed-up hours manually re-sourcing candidates the system already rejected.
Anat Keidar, Chief People Officer at DoorLoop, took a different approach by mandating human review at every AI screening decision point. That model works for smaller hiring volumes. For teams processing 500+ applications per role, the hybrid conditional model achieves similar quality control without requiring human eyes on every single submission.
The 25-Application Monthly Audit
No filtering model stays calibrated on its own. Candidate screening automation requires ongoing validation, and the most reliable method is unglamorous: pull 25–30 rejected applications each month and read them.
The protocol is straightforward. Select rejected applications at random from the previous 30 days. Review each one against the role requirements as a human would, ignoring whatever score or knockout flag the ATS assigned. Count how many you’d have moved to a phone screen. If more than 3–4 out of your sample would have warranted further review, your filters need immediate adjustment.
If more than 3–4 out of 25–30 randomly audited rejected applications would have warranted a phone screen, your filters need immediate adjustment.
This 12–16% false-negative threshold (3–4 out of 25–30) serves as an early warning system. Below that rate, your filters are performing within acceptable bounds. Above it, you’re losing pipeline quality faster than you’re gaining efficiency.
Teams that skip this audit tend to discover the problem months later, usually when hiring managers complain about weak candidate slates or when time-to-fill metrics balloon. By then, the best candidates have accepted offers elsewhere. Conversational AI tools have shown they can reduce candidate drop-off rates by up to 40%, but that engagement advantage disappears if your filters already eliminated qualified people before any outreach happened.
Keyword Mismatch and the Synonym Problem
ATS intake filtering failures aren’t always about filter logic. Sometimes the job description itself creates the mismatch. A posting that requires “stakeholder engagement” will screen out candidates whose resumes say “cross-functional collaboration,” even though the skills are functionally identical.
This synonym gap problem is well documented. Jobscan’s analysis of how applicant tracking systems process resumes confirms that ATS platforms filter large volumes of resumes based on keyword matching. When those keywords don’t account for the way real people describe their experience, qualified candidates fall through the cracks. The 15–25% error rate in AI-driven skill extraction compounds this because the parsing layer may misread or miss terms entirely, a challenge we’ve examined in our technical analysis of NLP parsing limitations.
Fixing keyword mismatches requires a systematic audit. Map every required skill in your job description to at least 2–3 synonym variants. “Project management” should also match “program management,” “delivery management,” and “project coordination.” “Data analysis” should capture “data analytics,” “business intelligence,” and “quantitative analysis.” Teams that implement this keyword gap audit process typically see a 15–20% increase in qualified candidates reaching the review stage.
Tip: When building synonym maps, pull language directly from the resumes of your best recent hires. Their phrasing reflects how strong candidates actually describe the skills you’re looking for.
The ATS market itself is evolving toward better handling of this problem. According to Tracker-rms’s 2026 industry statistics, the applicant tracking system market is prioritizing workflow consistency and clearer analytics over basic resume storage. Enterprise recruitment software increasingly includes semantic matching capabilities that go beyond exact keyword matches, though adoption and accuracy vary widely across vendors.
Recalibration as Ongoing Practice
The compound effect of filter drift, keyword mismatches, and parsing errors creates a system that degrades over time without active maintenance. Application volume management in 2026 requires treating filter calibration as a recurring operational task, not a one-time configuration during ATS implementation.
A practical cadence looks like this: monthly rejection audits (25–30 applications), quarterly keyword synonym reviews, and a full filter-logic review every time a role’s requirements change. Teams using Skillfuel’s pricing plans can build these review cycles into their ATS workflow directly, making the audit a scheduled task rather than something that depends on someone remembering to do it.
The 88% of employers who acknowledge their filters reject qualified candidates aren’t dealing with a technology problem. They’re dealing with a maintenance problem. The filters worked fine when they were first configured. They stopped working because nobody checked whether the assumptions baked into those rules still matched the reality of who was applying.
What The Data Doesn’t Tell Us
The available data on ATS filtering effectiveness has significant gaps. The 182% volume increase is well documented, and the 88% employer acknowledgment rate gives us a clear picture of how widespread the problem is. What we don’t have is granular data on how false-negative rates vary by industry, role level, or ATS vendor.
A healthcare system filtering nursing candidates with strict credential requirements operates under fundamentally different constraints than a tech company screening software engineers by keyword. The 15–25% parsing error rate is an aggregate figure, and the actual rate for any given ATS-and-role combination could be higher or lower. Similarly, the 30–40% candidate abandonment reduction attributed to hybrid models comes from organizations that invested significant effort in configuration. Teams that adopt the hybrid label without doing the configuration work should expect smaller improvements.
The numbers point clearly toward weighted scoring, monthly audits, and synonym mapping as the highest-impact interventions for high-volume hiring strategies. Whether those interventions close the gap entirely or reduce it from catastrophic to manageable depends on variables like job description quality, hiring manager alignment, and candidate market conditions that no single dataset has captured yet. The teams generating the best recruitment metrics in 2026 are the ones measuring their own filter performance monthly rather than relying on industry averages to tell them their system is working.