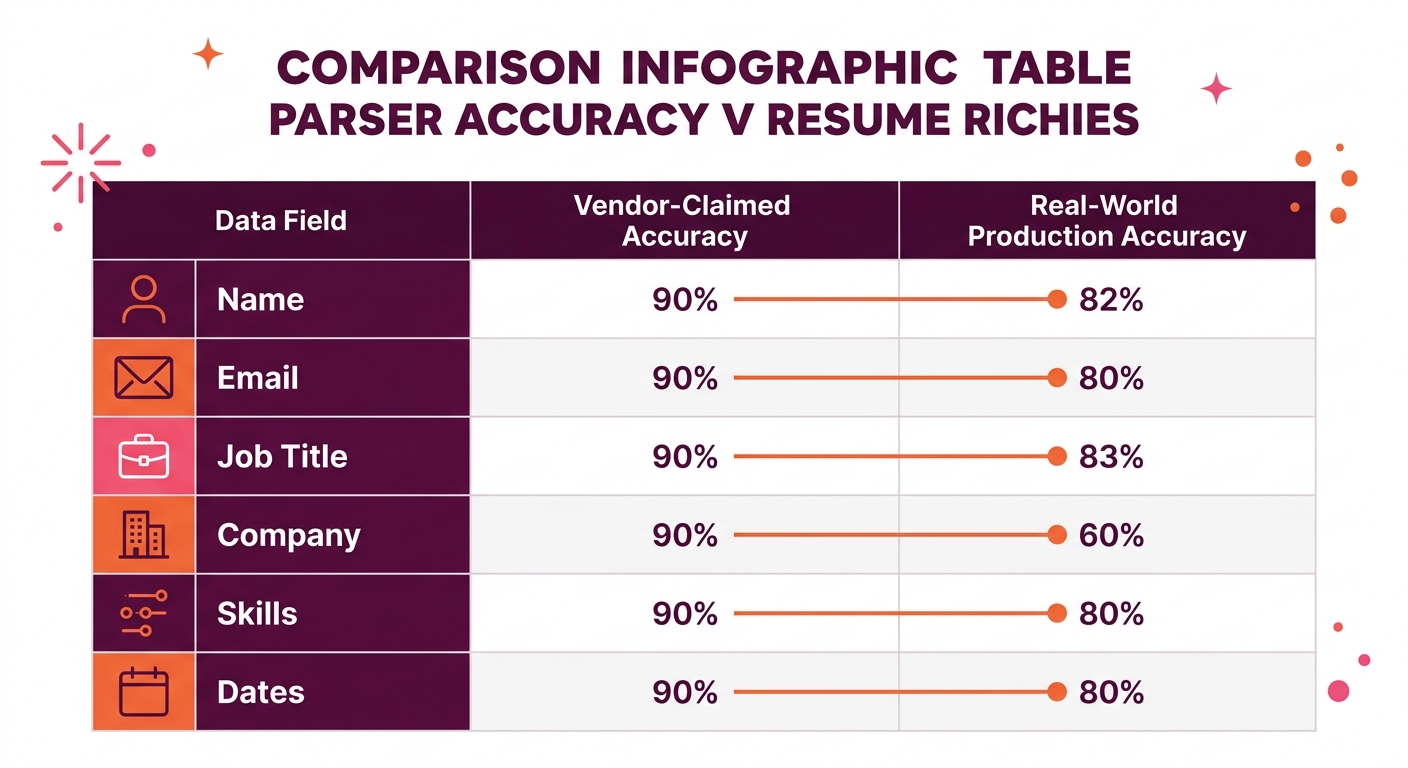
Field-level accuracy for skill extraction in production resume parsers ranges from 0.75 to 0.85, while basic fields like name and email hit 0.99 or higher. That gap is where your best candidates disappear. Every downstream matching decision inherits the error rate of the weakest extracted field.
The Friction Study That Quantified the Damage
A research paper published on arXiv titled “Quantifying Algorithmic Friction in Automated Resume Screening Systems” set out to measure something recruiters have complained about for years: exactly how often do automated screening systems reject candidates who are actually qualified? The researchers built a controlled evaluation framework, fed resumes through both keyword-based and semantic screening pipelines, and tracked where false negatives accumulated at each stage.
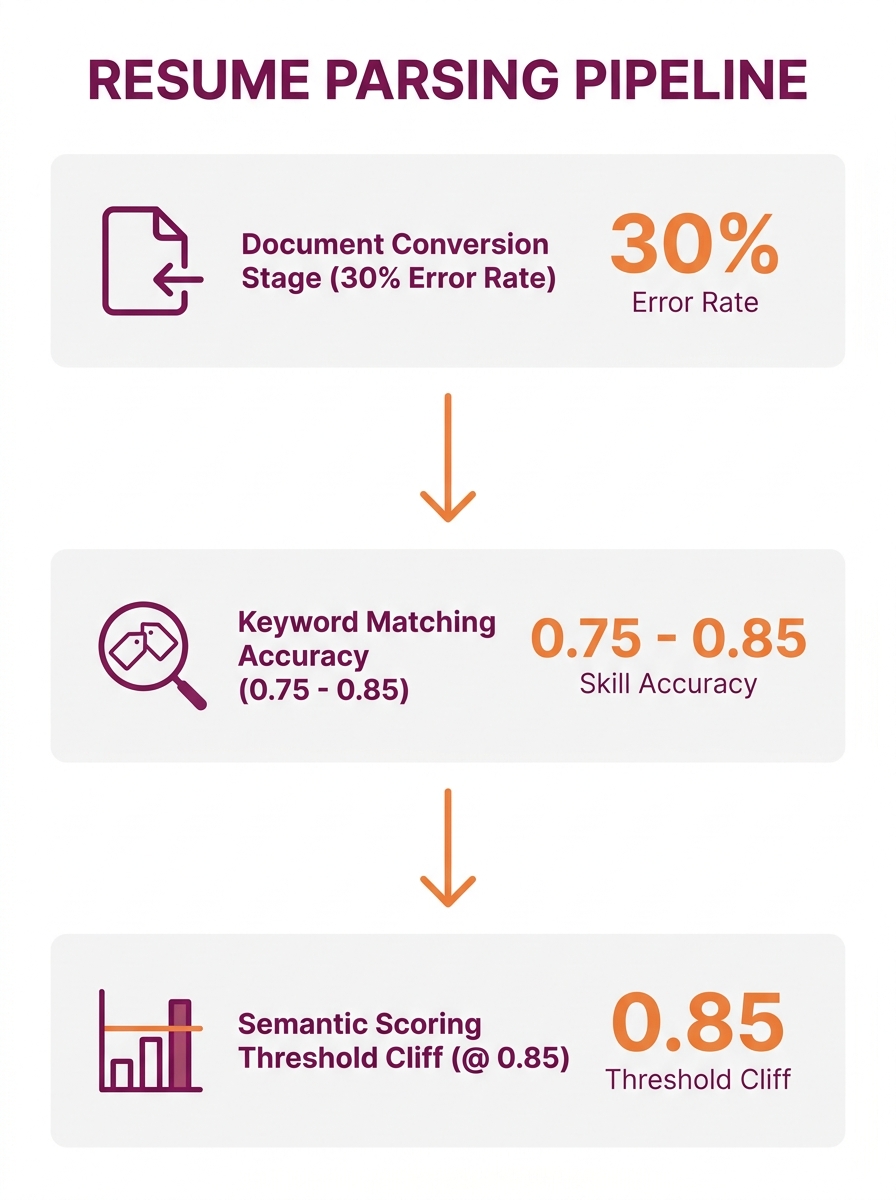
The findings confirmed the pattern. Residual false negatives under semantic screening were “primarily associated with genuinely ambiguous resumes lacking sufficient contextual detail,” according to the paper, rather than systematic representational failure. The researchers set their semantic similarity threshold at 0.85, meaning resumes scoring below that cutoff were automatically excluded from consideration. The threshold sounds reasonable in isolation. In practice, it created a cliff where candidates with unconventional career histories, cross-functional skill sets, or industry-switching backgrounds fell off.
The study also highlighted a fundamental architectural divide. Keyword-based filters match token presence, and they break on synonyms and context. A candidate listing “account management” gets screened out of a posting requiring “client relationship management,” even when the work is identical. Semantic matching systems try to solve this by evaluating meaning rather than exact strings, but they introduce their own failure modes at the threshold boundary. At a 0.85 cutoff, a product manager describing “care pathway optimization” won’t match a posting asking for “process improvement,” even though the meaning overlaps significantly.
30% of Errors Happen Before Any AI Runs
Why does resume parsing accuracy remain so inconsistent when the underlying models keep improving? Because 30% of all parsing errors originate from the initial document conversion stage, before any NLP logic fires. The AI that recruiters worry about never gets a chance to misread a skill. The document processor already mangled the input.
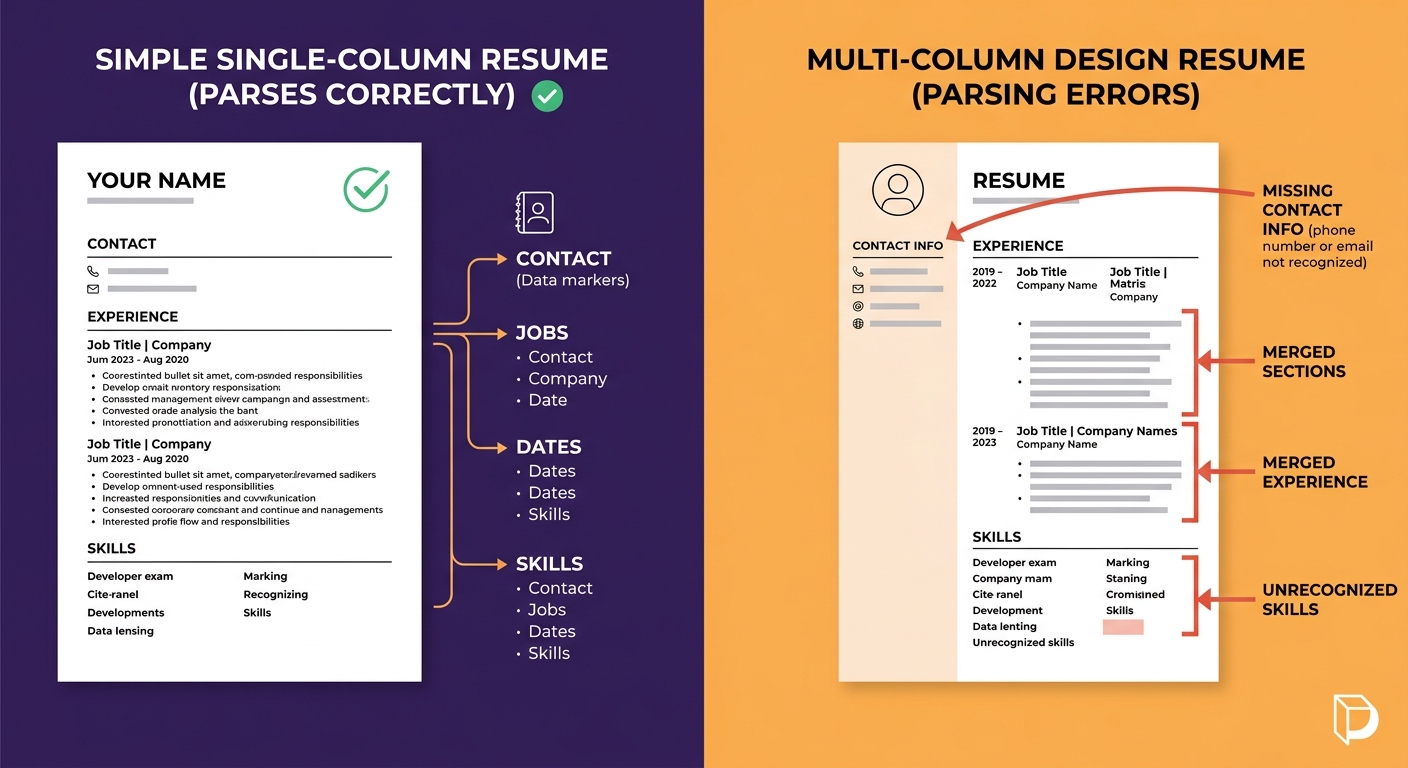
Testing found that five of eight ATS systems failed to extract candidate names when contact information appeared in headers or footers. Date formats create another class of candidate data extraction errors: mixing “March 2023” with “03/2023” with “2023-03” produces garbled employment timelines. Multi-column layouts, which designers love and parsers can’t process reliably, cause entire sections of work history to merge into a single text block or vanish entirely. Scanned PDFs introduce OCR noise that compounds through every downstream step.
According to a 2026 guide published by MiHCM, “layout-rich CVs, multi-column or decorative designs, scanned documents” remain the primary failure points for modern parsing systems, even those using embedding-based approaches. The NLP model receives whatever text the converter extracted. If the converter dropped a section, no amount of semantic intelligence recovers it.
This means the candidates most likely to lose data are the ones with the most polished, professionally designed resumes. A plain-text, single-column document from a junior applicant parses cleanly. A creative director’s portfolio-style PDF with sidebar skills sections and custom typography? The parser may extract 60% of the content and silently discard the rest. The result is that your ATS database contains a degraded version of the candidate’s actual qualifications, and every filtering step afterward operates on incomplete information.
Skill Extraction at the 0.75 Floor
Skill extraction is the specific field where NLP limitations in ATS systems cause the most damage to hiring outcomes. Basic contact fields (name, email, phone) parse at 0.99+ accuracy across most modern systems. Job titles and company names land around 0.90 to 0.95. Skills, the field that actually determines whether a candidate advances, sit between 0.75 and 0.85 depending on the parser, the resume format, and the specificity of the skill itself.
Research from the International Journal of Multidisciplinary Research and Growth Evaluation documented that even systems using BERT-based models for improved accuracy struggle with “inconsistent data formatting, multilingual text processing, and ethical challenges with AI-based hiring biases.” A separate evaluation published in IJARCCE found that “NLP algorithms occasionally struggled with ambiguous or poorly structured resumes, leading to less accurate parsing and extraction in some cases,” confirming the pattern across multiple research groups.
The 0.75 floor means roughly 1 in 4 skill mentions gets misclassified, missed, or mapped to the wrong taxonomy entry. For a resume listing 20 skills, that’s approximately 5 skills that may not make it into the structured data your ATS uses for filtering. If even 2 of those 5 are listed as requirements in the job description, the candidate gets filtered out despite being qualified. Semantic matching failures at this layer compound with the document conversion errors described above, creating a pipeline where qualified candidates face multiple independent chances of rejection.
A 0.75 skill extraction accuracy rate means roughly 1 in 4 skill mentions gets misclassified, missed, or mapped to the wrong taxonomy entry in your ATS.
And the problem is getting more adversarial. A Gartner survey found that 39% of candidates now use AI in their application process, generating resume text, cover letters, and assessment answers. This creates a feedback loop: candidates optimize language for parsers, parsers train on optimized language, and the gap between authentic career descriptions and machine-readable formatting keeps widening. Candidates who don’t use AI optimization tools face a parsing disadvantage against those who do, punishing the exact people who might be describing their experience most honestly.
Why Vendor Accuracy Claims Don’t Survive Your Applicant Pool
Parser vendors routinely advertise 95%+ accuracy rates. That number typically reflects F1 scores on standardized English-language benchmarks that skew toward simple, single-column formats with conventional section headers. Production performance on your actual applicant pool will differ, often significantly.
The gap exists for three measurable reasons. First, benchmark datasets underrepresent the format diversity of real applications. They rarely include scanned documents, multi-language resumes, or the creative layouts common in design, marketing, and communications roles. Second, the 95% figure usually reflects aggregate accuracy across all fields, where high-performing fields like name (0.99) and email (0.99) pull up the average and mask the 0.75 accuracy on skills. Third, benchmarks don’t account for the compounding effect described in Skillfuel’s own technical audit of parsing failures: “every extraction error from Layers One and Two compounds” through the filtering rules your team configures downstream.
The practical recommendation from production testing is a 50-CV benchmark protocol. Before purchasing or renewing a parser, pull 50 resumes from your own applicant population, covering the full range of formats, industries, and experience levels you actually receive. Run them through the parser. Manually compare extracted data against the source documents. Measure precision, recall, and F1 specifically on skills, because that’s where the damage concentrates. If the parser scores below 0.80 on skill extraction for your candidate mix, you’re systematically excluding qualified people.
Running regular audits on your keyword matching rules catches another layer of the problem, but the parser accuracy issue sits upstream of keyword configuration. You can have perfect keyword rules and still lose candidates if the parser never extracted the right skills from their resumes in the first place.
The Threshold Band the Friction Study Couldn’t Close
The arxiv researchers found that their semantic screening pipeline reduced false negatives compared to pure keyword matching. That was expected. What they couldn’t solve was the threshold problem. At 0.85 similarity, the system caught most strong matches. Lowering the threshold to 0.80 or 0.75 introduced more qualified candidates but also increased noise, making the recruiter’s review queue less useful. The “right” threshold depends entirely on the role, the applicant volume, and the cost of a missed hire versus the cost of reviewing extra candidates.
Modern systems using large language models add capability here. They handle context and normalization better than older keyword or earlier embedding models. But LLM-based parsing introduces new categories of errors: hallucinated fields (the parser “finds” a skill the candidate never listed), non-deterministic outputs (parsing the same resume twice produces different structured data), and higher processing latency that makes real-time feedback loops harder to build.
Warning: If your ATS vendor upgraded to LLM-based parsing, ask whether outputs are deterministic. Non-deterministic parsing means the same resume could produce different structured data on consecutive runs, creating inconsistent screening results.
The friction study’s most honest conclusion was that genuinely ambiguous resumes will always produce false negatives under automated screening. When a resume lacks sufficient contextual detail to connect experience to job requirements, no parser or matching algorithm can bridge that information gap. The system needs more data than the document contains. The recruiting teams that perform best are the ones combining parser output with human review at the threshold boundary, treating the 0.75 to 0.90 similarity band as a triage zone rather than an automatic reject pile. If you’ve already noticed patterns in how your employer brand attracts candidates your system then rejects, the parser threshold is likely one mechanism creating that disconnect. ATS parsing audits focused specifically on that middle band, where parser confidence is moderate and the risk of losing a strong candidate is highest, will catch problems that aggregate accuracy metrics completely obscure.