Resume parsers don’t read resumes. They decompose files into raw text, segment strings by pattern rules, and map fragments to database fields. At typical 60–70% field-level accuracy, roughly 1 in 3 candidate records in your ATS contains corrupted or misclassified data, and the failures happen at three auditable layers.
TL;DR: Resume parsing breaks at the file format layer, the field extraction layer, and the filter logic layer. Each layer produces candidate false negatives that recruiters never see. Running structured data extraction audits on all three is the only reliable way to measure and improve your actual resume parsing accuracy.
What the Parser Actually Does When It Receives a Resume
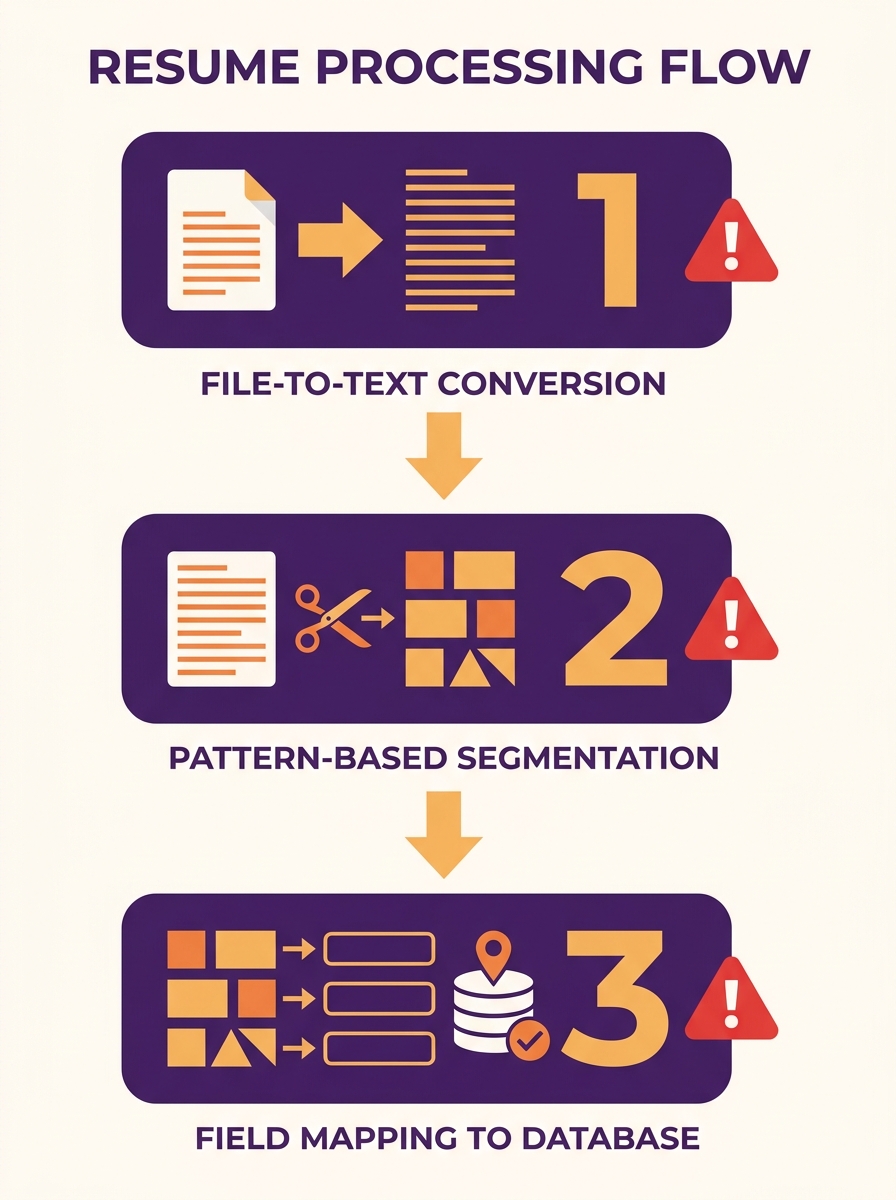
A parser converts a document file into a raw text string, splits that string into segments using pattern-matching rules (section headers, date patterns, line breaks), then writes each segment to a structured database field: name, email, employer, job title, dates, skills. Every step in that chain introduces error.
The parser looks for labels like “Experience” or “Education” as section delimiters. When a candidate writes “Where I’ve Worked” or “Professional Background,” the parser either guesses the mapping or skips the section entirely. This extraction runs before any recruiter touches the application. ATS software used by 98% of Fortune 500 companies performs this conversion automatically on every incoming resume. A 2026 KraftCV analysis found that 43% of resume rejections are preventable, caused by formatting and extraction errors rather than actual missing qualifications.
The distance between what a human sees on a printed resume and what the parser writes to your database is where candidate false negatives originate. Understanding each layer of that distance is what makes the difference between a pipeline that loses good people and one that doesn’t.
Layer One: File Format Determines Whether Parsing Can Even Start
The format a candidate submits controls whether the parser can access the text at all. A QuickCV test across 8 ATS systems found that plain text files produced the most consistent parsing across every platform tested. DOCX files from standard word processors hit the best balance between clean extraction and readable formatting. PDFs, the format most candidates actually prefer, introduce edge cases: embedded fonts that don’t map to Unicode, image-based text from scanned documents, and multi-column layouts that scramble reading order.
Here’s what that looks like in practice. A candidate submits a two-column PDF designed in Canva. The parser reads left-to-right across both columns simultaneously, mixing job titles with skill keywords and employment dates with employer names. The resulting database record is nonsense. But the recruiter filtering by “5+ years in project management” never sees this candidate because the experience field contains fragments of their skills section instead.
File naming adds another rejection point. Some ATS configurations enforce naming conventions specified in the job posting. If the posting requests “LastName_Position.pdf” and the candidate uploads “resume_final_v3.pdf,” the application can be disqualified before parsing begins.
| File Format | Parsing Consistency | Human Readability | Common Failure Mode |
|---|---|---|---|
| Plain Text (.txt) | Highest across all systems | Poor (no formatting) | None significant |
| DOCX (standard) | High | Good | Rare header/footer issues |
| PDF (text-based) | Moderate | Excellent | Embedded fonts, column scrambling |
| PDF (scanned/image) | Low | Excellent | OCR errors, missing text layer |
| Designed templates | Very low | Excellent | Column scrambling, icon misreads |
Organizations dealing with high parsing error rates at this layer have two realistic options: upgrade their ATS parser if the platform supports third-party parsing integration, or run resumes through a separate extraction tool before importing structured data via API or bulk upload. We’ve covered how parsing accuracy varies across ATS engines in detail, and the format layer is where the widest variation appears.
Layer Two: Field Extraction Maps Text to the Wrong Places
Even with a clean text string, the parser still has to decide which chunk belongs in which database field. This is where parsing configuration matters most, and where most ATS filtering failures accumulate without anyone noticing.
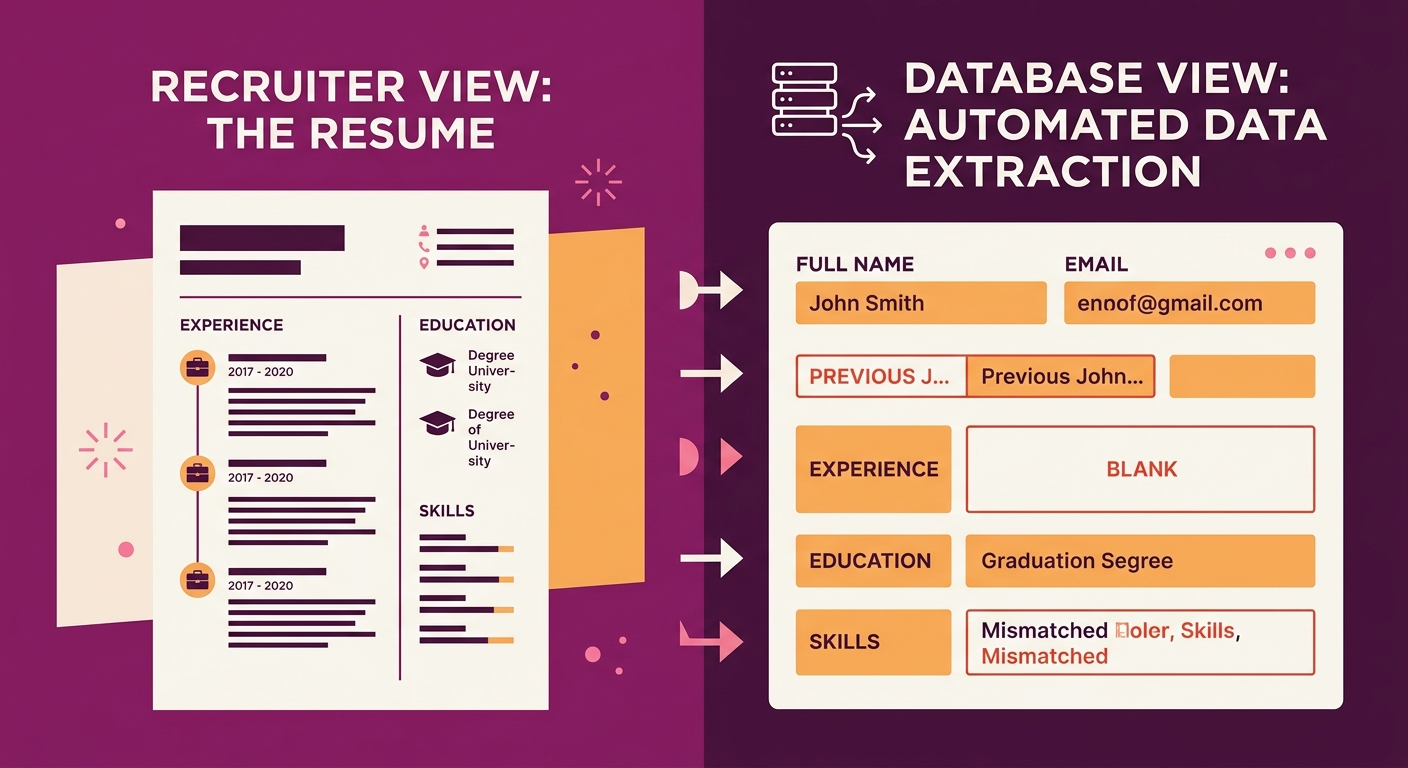
Contact information placed in document headers or footers gets skipped entirely on most systems. Parsers typically begin reading below the header boundary, so a candidate whose phone number and email sit in a Word document header ends up with a record that has no contact data. The recruiter sees a name with blank fields and moves on.
Date formats create another extraction failure. An 8-month testing study documented on Reddit found that inconsistent date formatting within a single resume causes parsing errors. “Jan 2020 to Mar 2023” in one entry and “2023-04 to 2024-12” in another confuses the pattern matcher. The parser may calculate negative tenure, skip the entry, or assign dates to the wrong employer.
Skills extraction carries its own failure modes. “Adobe Creative Cloud” and “Adobe Creative Suite” are different strings to a parser. A job posting specifying “Creative Cloud” won’t match a resume listing “Creative Suite” unless the system has a synonym dictionary, and most don’t by default. This exact-string matching problem generates false negatives at scale. The candidate is qualified. The parser disagrees.
Layer Three: Filter Logic Compounds Every Upstream Error
After parsing, your applicant tracking system applies whatever filtering rules your team has configured. This layer operates on the structured data the parser produced, so every extraction error from Layers One and Two compounds here.
Knockout questions are binary gates. As Jobscan’s research explains, ATS software doesn’t rank candidates or decide who is “better.” It gives recruiters a set of filters to enforce. If a recruiter sets a knockout question requiring PMP certification and a candidate’s certification was misparsed into the education field instead of the certifications field, that candidate gets automatically moved to “Not Hired.” The certification exists on the resume. The parser put it in the wrong place. The filter enforced exactly what it was told.
Harvard Business School research cited by HiringThing found that candidates were rejected outright because they did not exactly match the hiring criteria, often due to how those criteria were defined in the system rather than actual qualification gaps.
The parser put the certification in the wrong field. The filter enforced exactly what it was told. The candidate never knew they were rejected by a data mapping error.
This is the mechanism we explored when writing about how auto-extraction silently rejects strong candidates. Each layer trusts the output of the previous layer without verification, and that compounding trust is where qualified people vanish from your pipeline.
Running a Three-Layer Parsing Audit
The mechanism behind ATS filtering failures operates across three distinct layers, and fixing one without checking the others leaves blind spots. A structured approach to data extraction audits targets each layer independently. We call this the Three-Layer Parsing Audit: Format, Field-Mapping, and Filter-Logic.
Format audit. Submit 10 test resumes in 5 different formats (TXT, DOCX, single-column PDF, two-column PDF, and a designed template) through your ATS. Compare the parsed output against the original documents field by field. Count fields that extract correctly versus those that are blank, truncated, or misclassified. Your resume parsing accuracy at this layer should exceed 90% on DOCX and single-column PDF. Below that threshold, your parsing configuration needs adjustment or your parser needs replacement.
Field-mapping audit. Pull 10 real candidate records from your ATS and compare the structured database fields against the source resume files. Check contact information, employment dates (start and end), job titles, listed skills, and education credentials. Systems running traditional pattern-matching parsers typically land at 60–70% field-level accuracy. Systems using NLP-based extraction reach closer to 95% on well-structured formats. If your ATS implementation includes configurable parsing settings, this audit tells you which settings need tuning.
Filter-logic audit. Document every knockout question and required-field filter active across your open requisitions. For each filter, identify the specific parsed field it depends on. Then examine 5 candidate records that were auto-rejected to determine whether the rejection came from a genuine qualification gap or from a parsing error feeding bad data into a correctly configured filter. Given KraftCV’s finding that 43% of rejections are preventable, this step alone can recover a significant share of candidate false negatives.
Tip: SAP’s SuccessFactors requires separate integration configuration for each attachment type you want to extract. If you’ve only configured resume extraction, cover letters and supplemental documents aren’t being parsed at all. Check your integration settings against every document type your postings accept.
Where the Model Breaks
The Three-Layer Parsing Audit covers the majority of parsing failures for standard document-based applications, but it has limits. Video resumes, LinkedIn profile imports, and portfolio site links don’t follow the same extraction logic and need entirely separate audit procedures.
The framework also assumes your team can access raw parsed output. Some ATS platforms don’t expose the intermediate parsing layer to administrators, showing only the final structured record. In those systems, you can still run the format audit and filter-logic audit, but the field-mapping layer requires support tickets or API access to compare source documents against stored data.
And a single audit captures a snapshot, not a trend. Resume formatting conventions shift over time. Candidates increasingly use AI tools to generate resumes with nonstandard section headers. Parsing engines receive vendor updates that alter extraction behavior without warning. A quarterly audit cycle is the minimum frequency that catches meaningful drift. Teams processing more than 500 applications per month should run monthly spot checks on a random sample of 20 records.
The estimated $1.5 million annual cost of parsing-related hiring failures reflects lost productivity from unfilled roles, recruiter hours spent re-screening candidates who should have surfaced the first time, and the downstream cost of weaker hires when stronger ones were filtered out by technical errors. With teams already treating AI as a top recruitment priority, it’s worth remembering that every AI-powered screening feature, automated shortlist, and candidate scoring model operates on parsed data. If the parsing is wrong, every layer above it inherits that error. The mechanism is fixable, but only when you audit each layer on its own terms instead of treating “the ATS rejected them” as a single, opaque event.