Transformer-based resume parsers now extract candidate data at 97% accuracy, according to Hirize and vendor benchmarks tracked by Pin. Rule-based engines, the kind still running inside many enterprise ATS platforms, sit at 65%. That 32-point gap is the distance between finding your best applicant and never knowing they applied.
TL;DR: Resume parsing accuracy varies wildly depending on which generation of technology your ATS uses (65% for rule-based, 85% for early ML, 97% for transformer models), which file format candidates submit, and how consistently they format dates. ATS candidate screening failures are primarily extraction problems, not ranking problems. Two-column layouts fail on 7 out of 8 major platforms tested.
Three Generations of Parsing Technology
Your ATS parser falls into one of three technology generations, and each one produces dramatically different extraction results. Rule-based parsers, the oldest generation, rely on rigid pattern matching and predefined templates. They look for exact section headers (“Work Experience,” “Education”) and break when candidates deviate from expected formats. These systems extract data correctly about 65% of the time, per Pin’s 2026 parser benchmarks.
Early machine learning parsers improved that number to roughly 85% accuracy by training on large resume datasets and learning to recognize field boundaries even when headers varied. They handle some formatting variation but still struggle with creative layouts, non-standard section names (like “My Toolkit” instead of “Skills”), and embedded tables.
The current generation uses large language models and transformer architectures to hit 97% accuracy. These parsers understand context, recognize synonyms (“Python development” matching “Python scripting”), and handle more structural variation. Scale.jobs, for instance, exceeded 94% accuracy in keyword parsing across their testing. But here’s the critical detail: most enterprise ATS platforms haven’t upgraded their core parsing engines to this generation. Workday, Taleo, and many legacy systems still run older extraction logic under the hood, even when they’ve added AI scoring layers on top.

If you’ve been dealing with ATS auto-extraction errors silently rejecting strong candidates, the parser generation is usually the root cause, not the scoring algorithm.
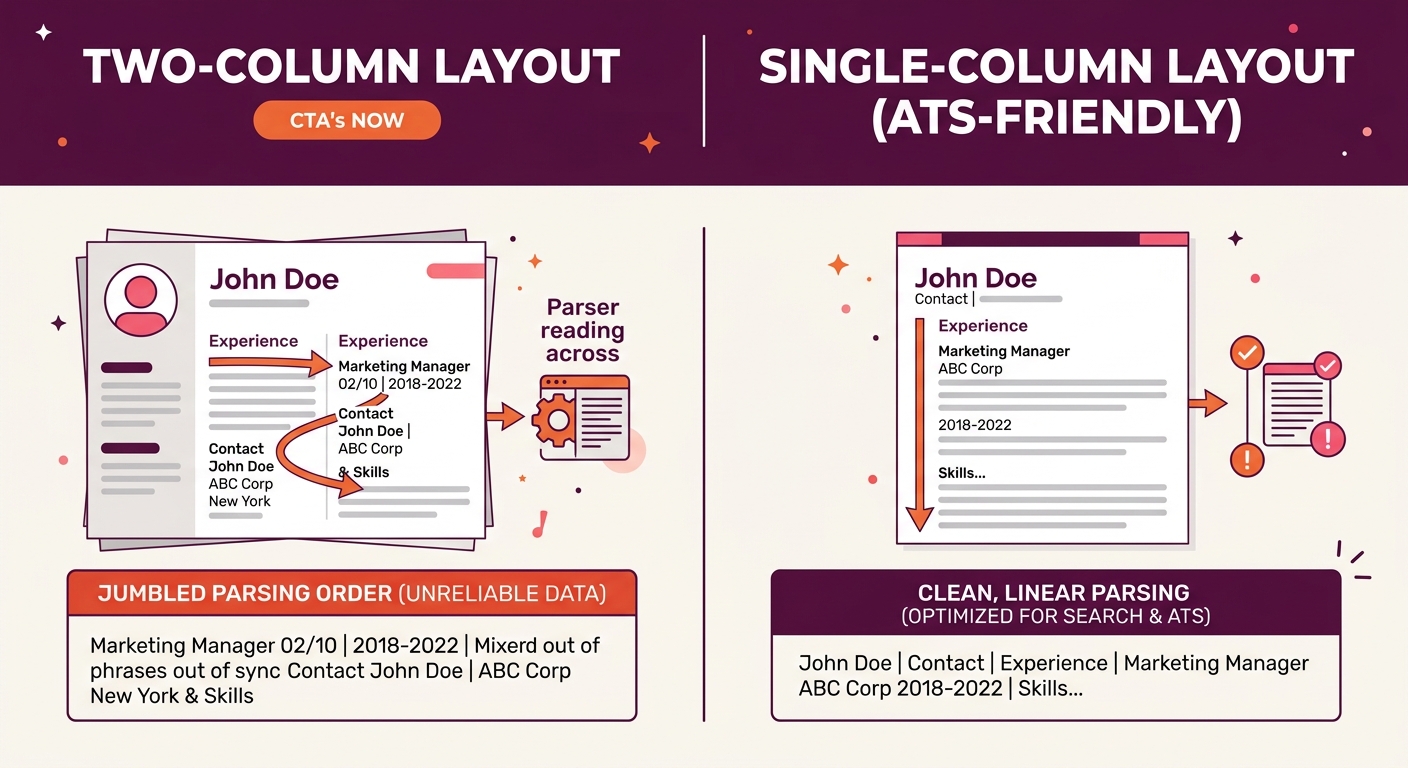
How Format Destroys Extraction Before Keywords Matter
The parsing engine never reaches your keywords if it can’t read the document structure. Testing across eight major ATS platforms reveals that .docx files outperform PDFs on six of those systems. Two-column layouts fail on seven of eight platforms, causing the parser to interleave text from both columns into a single garbled stream. Contact information placed in headers or footers gets skipped entirely on most systems because parsers often begin reading below the header boundary.
A 2026 KraftCV analysis found that 43% of resume rejections are preventable, stemming from formatting errors, parsing failures, missing keywords, bad timing, and volume overload. The formatting and parsing failures alone account for a significant share of that 43%.
Google Docs, despite being a simple word processor, produces some of the cleanest parser-friendly output when used with a single-column template and standard fonts. No sidebars, no text boxes, no icons. The format is boring by design standards and highly reliable by extraction standards.
Resumes with 25 to 35 role-specific keywords hit the optimal ATS match score in platforms using AI-assisted screening. Exceeding that threshold triggers keyword-stuffing detectors in 83% of companies now running AI screening tools. Old tricks like white-text keyword stuffing are detected and penalized by current systems, which evaluate contextual depth and reward quantified achievements over keyword repetition.
The Date Calculation Problem
Why does parsing break at the experience-calculation level? Because parsers treat date formats as data fields with strict expected patterns, and candidates routinely mix formats across their work history. One Reddit user who spent eight months testing ATS parsing across multiple platforms documented a stark example: “I saw resumes where candidates had 8 years of experience but the system calculated 3, because they mixed ‘Jan 2019,’ ‘2019-01,’ and ‘January ’19’ across different roles.”
That’s a 62.5% error in total experience calculation from a formatting inconsistency that takes a human two seconds to read correctly. The parser, lacking the contextual reasoning to normalize three different date representations, either drops the inconsistent entries or misaligns their start and end points.
The same tester found that “Month Year” format (e.g., “Jan 2020 – Mar 2023”) parsed most reliably across all systems tested. When candidates used numeric formats like 01/2020, slash-separated patterns occasionally confused parsers that interpreted them as day/month rather than month/year, creating phantom one-day employment stints or multi-year gaps.
Exact job title matches between the resume header and the job posting increase callbacks by 10.6x, according to analysis cited in Brave’s aggregated ATS research. This means the parser’s title-extraction accuracy directly controls whether a candidate surfaces in recruiter searches. Workday, for example, weights job title match heavily in its ranking algorithm. A garbled title field cascades into reduced visibility across every subsequent search.
Platform-by-Platform Resume Data Extraction Comparison
Jobscan’s testing showed an average parser pass rate of 90.7%, but performance varies significantly across platforms. Lever hit 93%, Greenhouse landed at 91%, and Workday trailed at 88%. Those percentages represent the rate at which correctly formatted resumes had their key fields accurately extracted.
| Platform | Parser Pass Rate | .docx Handling | Two-Column Support | Title-Match Weight | Best For |
|---|---|---|---|---|---|
| Workday | 88% | Good | Poor | Very High | Enterprise (5,000+ employees) |
| Greenhouse | 91% | Good | Moderate | Moderate | Mid-to-large tech companies |
| Lever | 93% | Good | Moderate | Moderate | Mid-size tech, recruiter-workflow focus |
| Taleo (Oracle) | Below avg | Strict | Very Poor | High | Legacy enterprise installs |
| SmartRecruiters | Good | Good | Moderate | Moderate | Mid-market, integration-heavy |
MokaHR, Greenhouse, Lever, Workday, and SmartRecruiters rank as top picks for parsing accuracy, automation depth, and integrations in MokaHR’s benchmarking, with MokaHR claiming up to 3x faster candidate screening than competitors. Taleo remains the most aggressive in its parsing requirements; non-standard headers, text boxes, and two-column layouts cause frequent extraction failures that go unreported to the candidate.
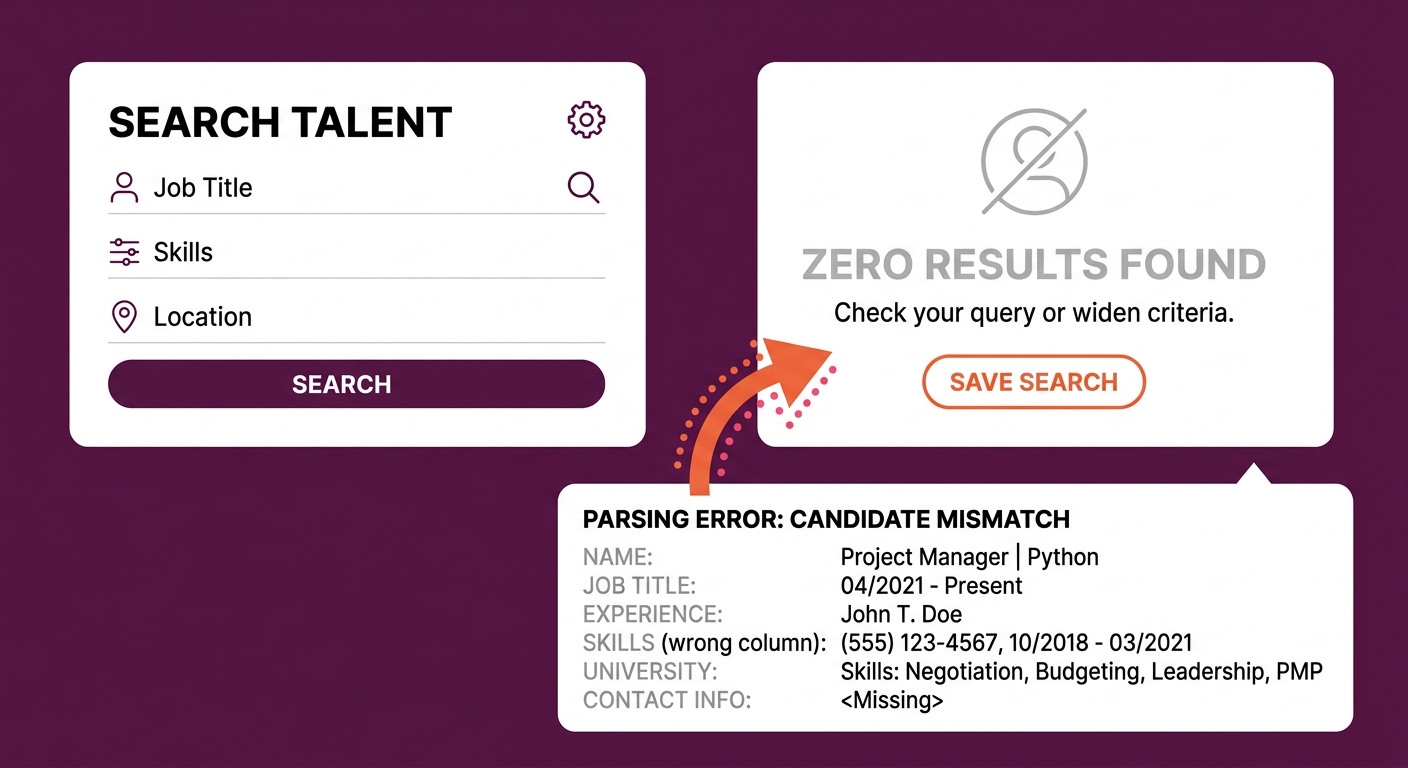
The 92% of recruiters who use their ATS as a searchable database rather than an auto-rejection tool face a specific consequence of poor parsing: the candidate isn’t rejected, they become invisible. Their record exists in the system, but garbled fields mean they never surface in keyword searches. This is the primary mechanism behind ATS candidate screening failures at scale. If your team is evaluating platforms, the configuration details at implementation matter as much as the vendor’s published accuracy numbers.
Auto-Extraction Bias and the Compliance Dimension
Traditional ATS platforms miss qualified candidates because of rigid filtering mechanisms and poor contextual understanding, according to research from Talent Business Partners. This auto-extraction bias compounds existing demographic disparities. Candidates from non-traditional educational backgrounds, career changers, and workers from industries with different resume conventions are disproportionately affected by parsers trained on narrow resume templates.
The compliance risk is real and growing. In 2023, the EEOC settled its first AI-related discrimination case against iTutorGroup, which had used software that automatically rejected female applicants over 55 and male applicants over 60. The company paid $365,000. Sanford Heisler Sharp, an employment law firm, has warned that these systems “often make decisions without transparency or human review,” creating legal exposure that recent AI discrimination rulings have begun to clarify.
Auto-extraction bias doesn’t look like rejection. It looks like invisibility: a qualified candidate sitting in your database, fully searchable by a human, completely invisible to your parser’s search index.
Harvard research has shown that applicant tracking systems filter out millions of qualified workers before any human reviewer sees their application. The parsing layer is where that filtering begins, and it operates on format and structure long before any skills-based evaluation occurs.
For teams running high-volume hiring, a free ATS with modern parsing can outperform an expensive legacy system with outdated extraction logic. The parser generation matters more than the price tag.
Where the Model Breaks
Every parsing engine, including the 97%-accuracy transformer models, fails in predictable spots. Non-Latin character sets in names and addresses cause garbled contact fields across all platforms tested. Resumes with embedded images (logos, headshots, skill-bar graphics) produce silent extraction failures where the parser skips the image region and concatenates the surrounding text incorrectly. Candidates who use functional resume formats (skills-first, with employment history compressed at the bottom) see lower extraction rates because most parsers are trained on reverse-chronological structures.
The 60-to-90-second manual review checkpoint recommended for phone-screen candidates catches the extraction errors that matter most: missing skills, garbled employment history, and invisible contact details. Building a parsing audit into your workflow that flags records where fewer than 80% of expected fields populated correctly and routes those to manual review is the most reliable safeguard. Even at 97% accuracy, a 3% failure rate across 1,000 applicants means 30 candidates with corrupted records. Some of those 30 are your best people.
The industry is moving toward context-aware matching and AI-driven skill verification that reduces dependence on parsed text fields entirely. But that transition is years from full adoption. Right now, your ATS parser is the gatekeeper, and understanding whether it runs 65%, 85%, or 97% extraction logic determines how many qualified candidates your team actually sees.