The standard hybrid screening model — auto-advance the top 15%, auto-reject the bottom 55%, send the middle band to a recruiter — assumes the parser scored candidates correctly in the first place. That assumption is wrong often enough to bury your best applicants before any human touches their file.
TL;DR: Hybrid screening workflows fail when they trust ATS parsing output as ground truth. Parsers misread contact details, scramble employment dates, and score qualified candidates at zero. A functional hybrid workflow places manual review gates before the sort, not after, and audits parser confidence at the field level rather than the candidate level.
The Parser Breaks Before the Recruiter Ever Looks
Five of eight tested ATS platforms failed to extract candidate names correctly when contact information was formatted in non-standard layouts, according to research on ATS data extraction errors. Names. The most basic field. If your parser can’t reliably capture who someone is, every downstream score attached to that record is suspect.
The damage compounds across every field the parser touches. Two-column layouts, text boxes, headers, and footers remain critical failure points because parsers read left-to-right, top-to-bottom. A resume with a sidebar skills section gets its content scrambled into adjacent job descriptions, producing nonsense that the scoring engine then evaluates as if it were real data. Current parsing benchmarks show a 15–25% error rate in AI-driven skill extraction, which means roughly one in five skill tags attached to a candidate profile is either wrong, duplicated, or missing entirely.
And here’s where the hybrid model’s logic falls apart: when the parser miscalculates years of experience because of inconsistent date formats (mixing “Jan 2019” with “2019-01,” for example), the system ranks that resume below candidates whose dates parsed cleanly, even when actual experience matches the role. The candidate doesn’t land in the “middle band” for human review. They land in the auto-reject pile. Your recruiter never knows they existed.
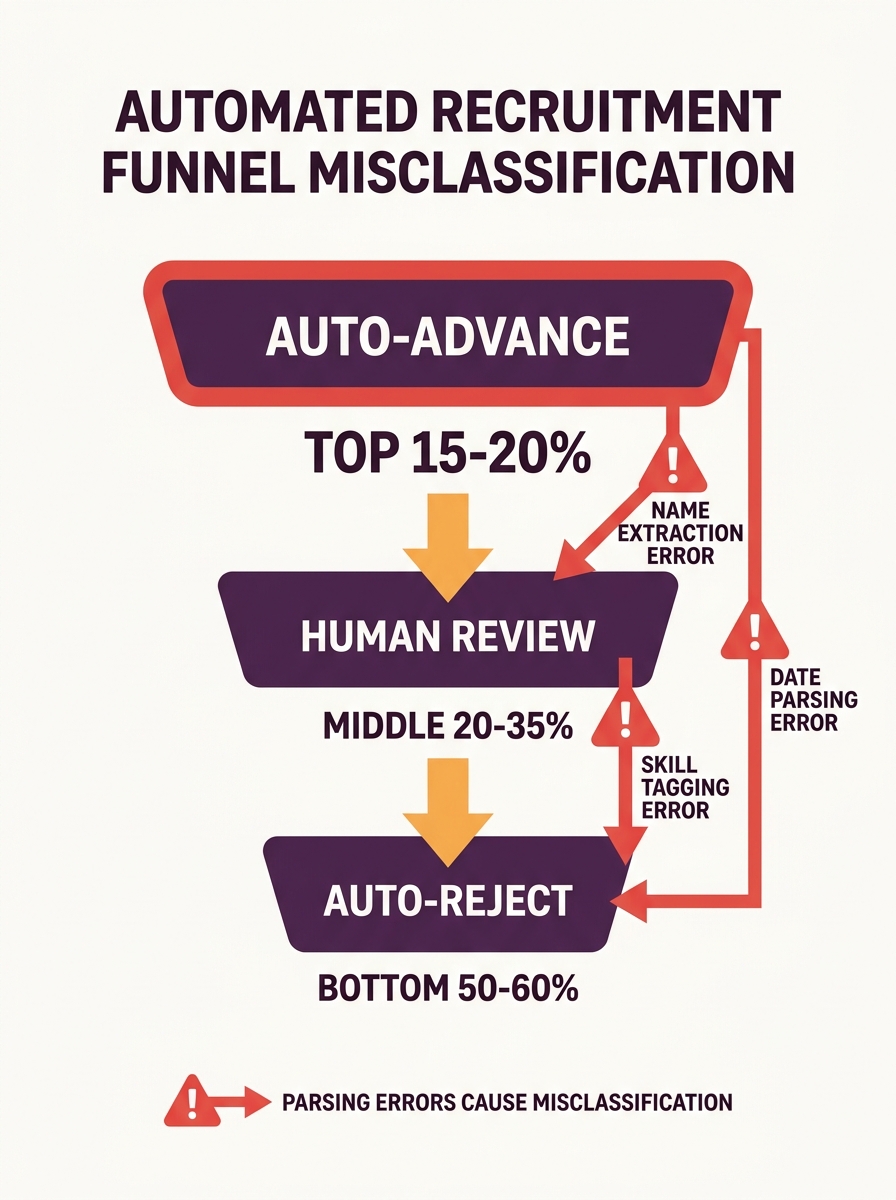
This is the core problem with treating parser output as the truth layer beneath your screening workflow. The best applicant might already be in your database, scored at zero, buried where no search query will ever return them. ATS candidate recovery becomes impossible when the record itself is corrupted at ingestion.
NLP Can Read Resumes but Cannot Read Careers
Why does parsing break beyond simple formatting issues? Because the NLP engines powering modern ATS platforms face a fundamental constraint: they handle ambiguity poorly. Professionals working in Natural Language Processing describe the core challenges as understanding ambiguities in human language and managing large, unstructured datasets. Resumes are exactly the kind of unstructured, ambiguous document that stress-tests every weakness in the technology.
NLP in recruitment transforms unstructured communications into analyzable data, generating insights about candidate skills and experience. That transformation works well for straightforward career paths: linear progressions, standard job titles, and industry-recognized certifications. It works badly for career changers, military-to-civilian transitions, candidates from non-English-speaking backgrounds, and anyone whose resume tells a story the parser wasn’t trained on.
Consider the NLP limitations in recruitment that appear at the scoring layer. Platforms increasingly map skills to structured taxonomies like EMSI Burning Glass or O*NET, and candidates whose resumes use synonyms within those taxonomies get matched. But ML-based platforms score 10.6x higher for candidates who use the exact job title from the posting in their resume header, compared to synonyms like “Product Lead” for “Senior Product Manager.” The technology rewards phrasing conformity, which has nothing to do with whether someone can do the job.
A 15–25% error rate in skill extraction means roughly one in five skill tags attached to a candidate profile is wrong, duplicated, or missing.
This creates a specific, measurable bias: candidates who know how to format for ATS parsers rank higher than candidates who don’t. The 92% of recruiting leaders who report that AI-generated resumes are now common are seeing the downstream effect. Candidates who use AI to write ATS-optimized resumes game the parser successfully, pushing organically written resumes from qualified people further down the stack. Your hybrid workflow’s “top 15%” auto-advance tier fills up with well-formatted mediocrity, while experienced candidates who wrote their own resumes in a two-column Word template get auto-rejected.

When DoorLoop deployed AI tools for sourcing and first-pass screening, they mandated human review at every AI screening stage specifically to address bias risk from these kinds of failures. That decision reflects a growing recognition that resume parsing accuracy degrades on exactly the candidate profiles you most want to catch.
Where Manual Review Gates Actually Belong
The conventional workflow puts human reviewers after the parser has already sorted candidates into tiers. According to widely cited best practices for AI resume screening, the top 15–20% auto-advance to phone screens, the bottom 50–60% get auto-rejected, and the middle 20–35% goes to human review. This structure assumes the tiers are correct. Given the parsing error rates documented above, that assumption fails for a meaningful percentage of your applicant pool.
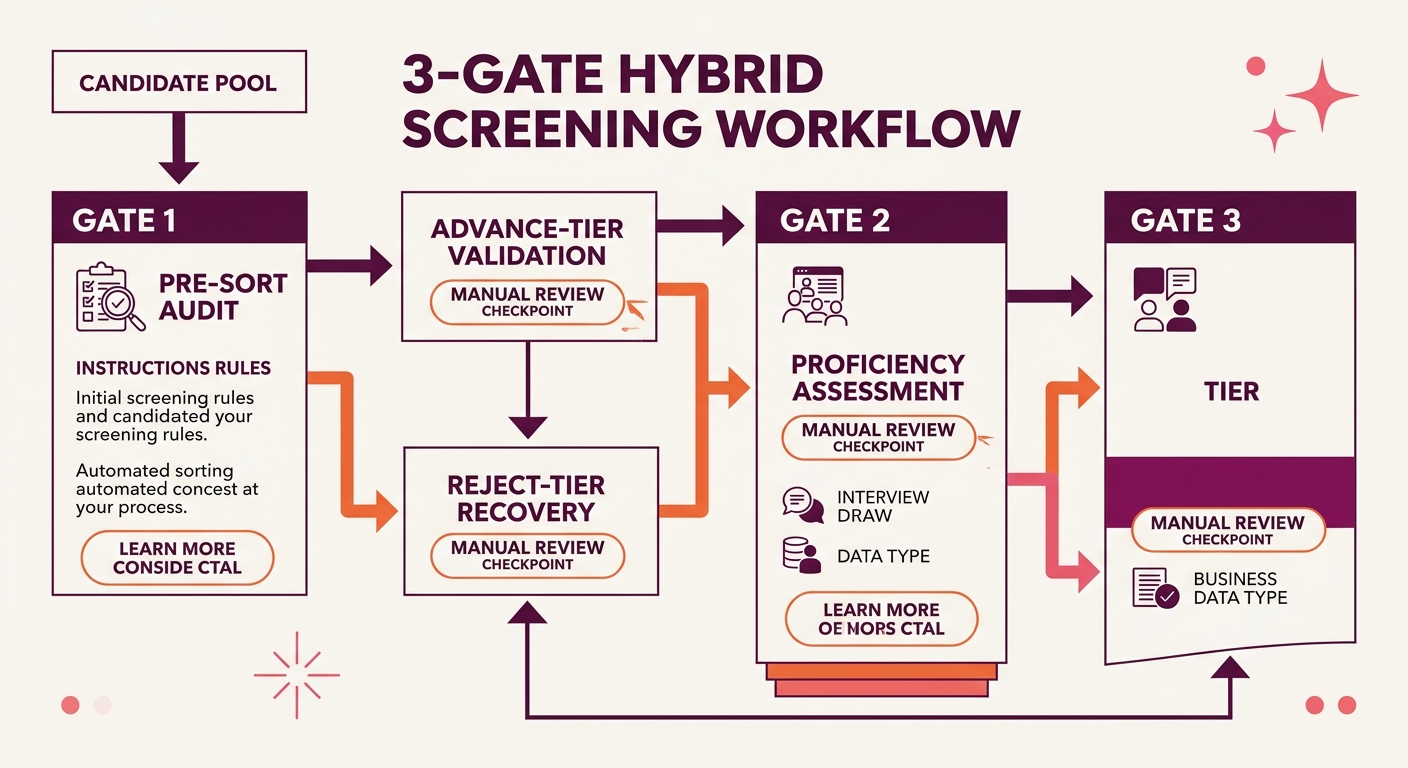
A better hybrid screening workflow places manual review gates at three specific points, what you might think of as a Field-Level Confidence Audit:
- Pre-sort audit (before scoring): Sample 10% of parsed resumes and compare extracted fields against the original document. Track accuracy rates for name, email, phone, dates, job titles, and skills separately. If any field drops below 90% accuracy, your scoring layer is working with bad data and your tier assignments are unreliable.
- Reject-tier recovery (after scoring): Pull a random sample from the auto-reject tier weekly and have a recruiter review the original documents, not the parsed data. You’re looking for candidates whose qualifications are visible in the PDF but invisible in the parsed record. Track how many recoverable candidates you find per 100 reviewed. If that number exceeds 5, your parser needs reconfiguration or replacement.
- Advance-tier validation (before interview scheduling): Spot-check the auto-advance tier for candidates whose parsed profiles look strong but whose original resumes reveal formatting-inflated scores. This catches the AI-generated resume problem before it wastes interviewer time.
DISHER Talent’s analysis of automated versus human screening described the ideal state well: “Automation weeds out unqualified applicants; humans focus on targeted, relationship-building evaluation.” The insight is correct, but the implementation matters. If humans only review the middle band, they’re reviewing a contaminated sample. Some of those candidates belong in the top tier, others in the bottom, and the contamination comes from the parser, not the candidates.
Tip: Track your reject-tier recovery rate monthly. If you’re consistently finding more than 5 qualified candidates per 100 sampled from auto-reject, your parser configuration is the bottleneck, and no amount of human review of the middle band will compensate.
Companies that handle high application volumes feel this pressure most acutely. When you’re processing thousands of resumes per open role, even a 5% parsing error rate means dozens of qualified candidates sorted into the wrong tier every cycle. And for teams using recruitment software for small businesses, where every hire carries outsized impact, a single misclassified candidate can mean the difference between filling a role in three weeks and reopening the search.
The data on what works supports this approach. Case studies show companies reducing hiring time by up to 80% by automating initial screening, according to DISHER Talent’s research. But that speed gain only holds when the automation is accurate. An 80% time reduction built on a 15–25% error rate means you’re making faster wrong decisions. The hybrid model needs to be designed so humans verify the machine’s data layer, not just its output rankings.
Building a company job portal that feeds clean, consistently formatted applications into your ATS also helps. When you control the input form, you reduce the formatting variability that breaks parsers. Structured application fields for dates, titles, and skills bypass the parsing step entirely for those data points, leaving the parser to handle only the unstructured sections like work descriptions and cover letters.
The Claim, Revisited
The hybrid screening workflow, as typically implemented, contains a structural flaw: it trusts the parser’s output as the foundation for human decision-making. The three-tier model (auto-advance, human review, auto-reject) works logically but fails empirically because the sorting mechanism has a documented error rate high enough to misclassify qualified candidates at scale.
The fix isn’t to abandon automation. Automated resume screening saves time and money by quickly short-listing candidates, and no recruiter wants to go back to reading every resume manually. The fix is to move your manual review gates upstream, where they can catch parser errors before those errors cascade into bad tier assignments. Audit the parsed data against source documents. Sample your reject tier for recoverable candidates. Validate your advance tier for formatting-inflated scores.
The conventional wisdom about hybrid workflows holds, sort of. Humans and machines together do screen better than either alone. But the conventional implementation puts humans in the wrong place. Move them to where the data breaks, and your hybrid screening workflow will actually do what it was designed to do: surface the candidates who deserve to be seen.