Testing across eight major ATS platforms shows that .docx files outperform PDFs in text extraction on six of those eight systems, and two-column resume layouts fail to parse correctly on seven of eight. These formatting decisions, made by candidates who don’t know the rules, destroy candidate profile completeness before a recruiter opens a single file.
TL;DR: ATS data extraction errors silently degrade candidate records, and recruiters have three realistic paths to fix it: enforcing strict resume formatting for applicants, upgrading parsing technology, or building manual review checkpoints. Each approach carries real tradeoffs in candidate experience, cost, and hiring speed.
Where Parsing Actually Breaks Down
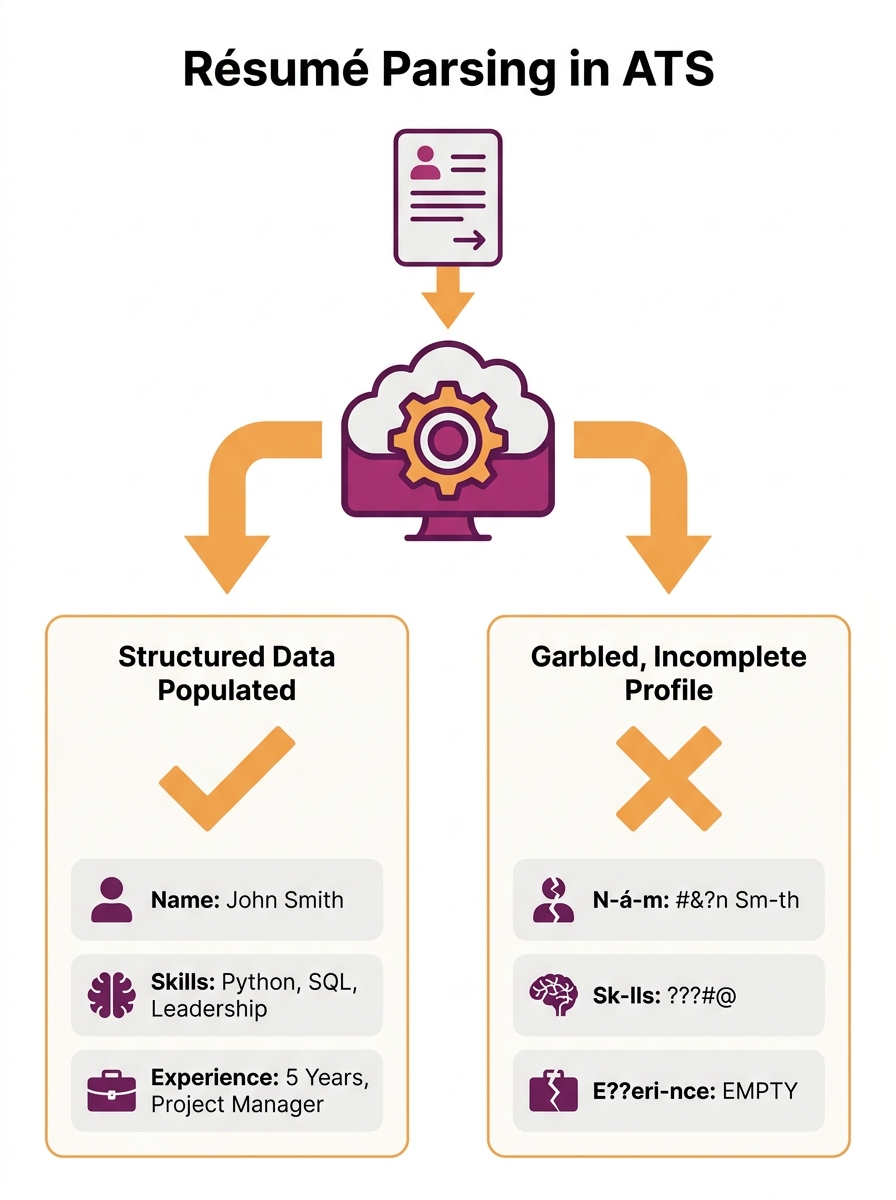
Why does the parsing problem persist in systems recruiters depend on daily? Because ATS platforms don’t read resumes the way humans do. The system runs parsing software that extracts structured data, and as Hireflow’s engineering analysis explains, “this extracted data is what recruiters actually search through, filter by, and rank. If parsing fails, your resume becomes unreadable to the system.”
The scope of the damage is specific. ATS data extraction errors include misread contact details (five of eight tested systems failed to extract candidate names when information sat in headers or footers), mangled employment dates (mixing formats like “March 2023,” “03/2023,” and “3-23” within one document triggers false gap calculations), and invisible skills. A developer who spent eight months running thousands of parsing tests against Workday, Greenhouse, Lever, iCIMS, and Taleo reported the results publicly: creative section headers like “My Toolkit” were missed entirely by three systems or misclassified, effectively hiding skills data from every recruiter search.
The widely cited “75% auto-rejection” statistic is misleading, according to that same testing. The real number: 92% of recruiters don’t use ATS for outright auto-rejection. They use the system as a search database. Candidates whose resumes parse poorly never appear in results. The system doesn’t reject them. It renders them invisible.
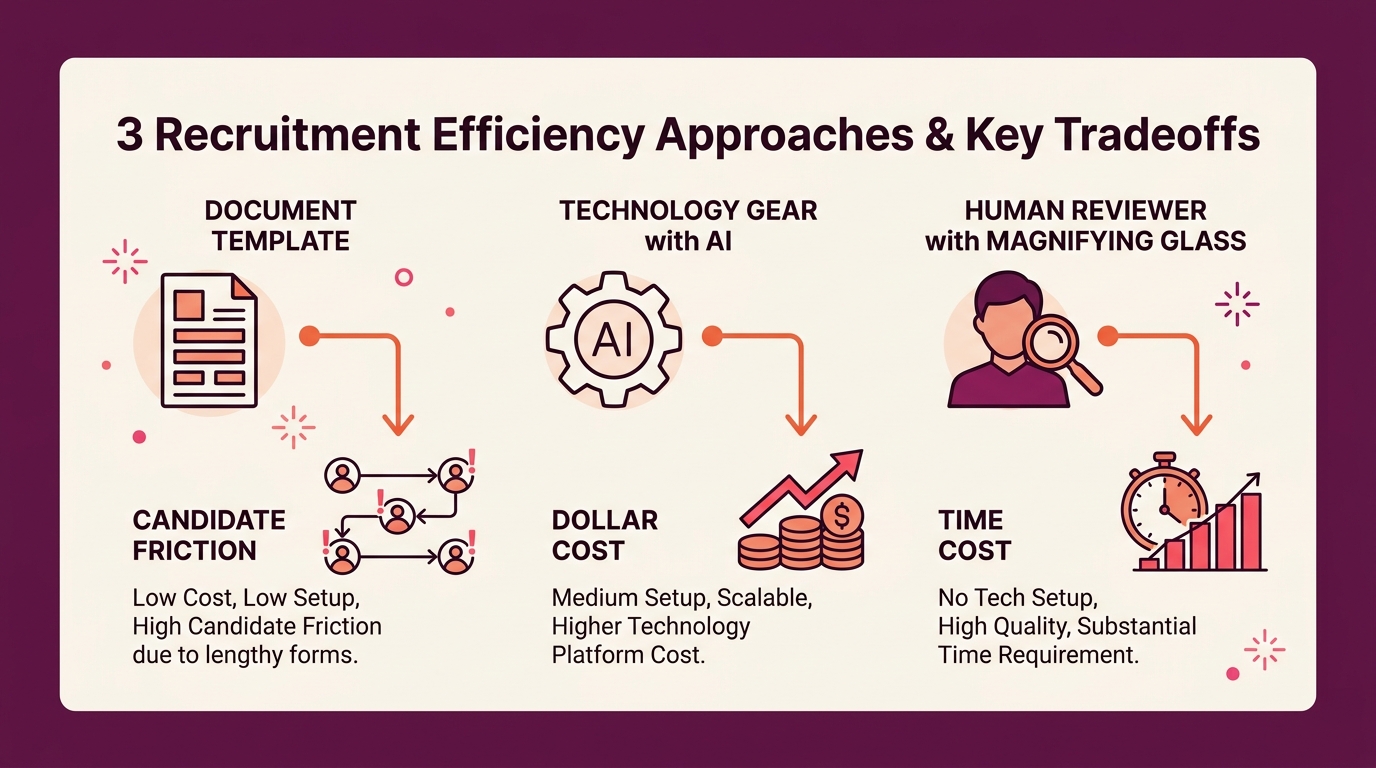
For recruiting teams trying to improve resume parsing accuracy, three distinct strategies emerge. Each solves a different piece of the problem, and each comes with costs worth weighing honestly.
Option 1: Enforce Structured Resume Formatting for Applicants
The simplest fix puts the burden on candidates. You publish formatting guidelines, require .docx uploads, specify standard section headers like “Work Experience” and “Skills,” and some companies go further by providing downloadable resume templates.
This approach works. Resumes built on single-column layouts with standard headers parse reliably across all major platforms. Candidates who match the exact job title from the posting see a 10.6x increase in callbacks, and resumes carrying 25 to 35 role-specific keywords hit optimal ATS match scores without triggering keyword-stuffing detectors. When every applicant follows the same structural rules, your system’s candidate ranking mechanics operate on clean data.
The tradeoff hits candidate experience hard. Allsorter’s extraction guidance warns that “any information embedded in visuals may be completely missed by resume extraction software,” but most candidates don’t know this rule exists. Requiring rigid formatting punishes the 60% to 70% of applicants who’ve never heard of structured resume formatting for ATS. Senior candidates with designed PDF portfolios get silently downranked. International applicants using non-US date formats see their timelines misread. Creative professionals face an impossible choice between demonstrating their work and being findable.
If your screening process already strains candidate experience, adding formatting requirements introduces another friction point. The candidates most likely to comply are early-career applicants who’ve been coached on ATS optimization. The candidates least likely to comply are experienced professionals who haven’t applied for a job in five years.
Best for: High-volume hiring pipelines (100+ applications per role) where candidate supply exceeds demand and formatting instructions can be embedded directly in the application flow.
Option 2: Upgrade Your Parsing Technology
The second approach attacks the problem from the system side. Modern AI-powered parsing engines handle a wider range of formats, extract data from PDFs with higher fidelity, and recognize non-standard section headers that older keyword-matching parsers miss entirely.
The improvement is measurable. Older parsers using rigid pattern-matching fail on two-column layouts in seven of eight ATS platforms. Newer NLP-based engines interpret contextual clues, identifying that “My Professional Background” functions identically to “Work Experience” and extracting accordingly. These engines also handle ligature rendering issues that silently corrupt parsed text. One user in r/resumes documented the problem: “Your resume looks fine but ATS reads like ‘communica on’ instead of ‘communication.’ You lose keywords and never know.” Advanced parsers running OCR alongside text extraction catch these corruptions before they pollute the database.

The cost is real, both in dollars and implementation complexity. Swapping parsing engines means migrating candidate data, retraining recruiters on new search behaviors, and accepting a transition period where your recruitment process temporarily slows. Pricing varies widely: some ATS vendors include upgraded parsing in their enterprise tier, while standalone parsing APIs charge per resume processed. For a team handling 5,000 applications per month, even $0.10 per parse adds $6,000 annually.
And better parsing doesn’t eliminate every ATS data extraction error. File format remains a hard constraint. Resumes submitted as .jpg images, .rtf files, or Adobe InDesign documents still trigger immediate parsing failures regardless of engine sophistication. Contact information buried in image-based letterheads stays invisible. The technology gap shrinks, but a gap remains.
Best for: Mid-size teams (20 to 80 open roles) with budget to invest in ATS infrastructure and a candidate pool that skews toward experienced professionals who won’t tolerate rigid formatting mandates.
Option 3: Build Manual Review Checkpoints
The system doesn’t reject candidates. It renders them invisible. Recruiters who never check the gap between uploaded files and parsed records don’t know what they’re missing.
The third approach accepts that parsing will always produce errors and designs the workflow to catch them. Instead of perfecting extraction, you add human review at specific points in the funnel where parsing failures cause the most damage.
The simplest version: recruiters compare the original uploaded resume against the parsed candidate record for every applicant who reaches the phone-screen stage. This takes 60 to 90 seconds per candidate and catches the ATS data extraction errors that matter most (missing skills, garbled employment history, invisible contact details). A more structured version builds a parsing audit into your applicant tracking system’s workflow, flagging records where fewer than 80% of expected fields populated correctly and routing those to a manual review queue.
Harvard Business School research documented that automated filtering systems exclude millions of qualified workers before human review, a finding that reinforces why checkpoints matter. If your ATS filters out candidates with parsing gaps in their work history, you’re likely rejecting people whose actual resumes show continuous employment. Configuring knockout questions carefully helps, but it doesn’t address the underlying data quality problem.
The tradeoff is time. Manual review doesn’t scale. At 90 seconds per candidate and 200 applications per role, you’re looking at five hours of parsing review per position. Multiply that across 30 open roles and your recruiting team just lost 150 hours per month to data cleanup. Teams already seeing recruiter call time climb to 286 minutes per week can’t easily absorb additional workload.
Best for: Low-volume, high-stakes hiring (executive search, specialized technical roles, senior leadership) where every missed candidate represents significant opportunity cost and volume is low enough for per-candidate review.
Side-by-Side Comparison
| Factor | Enforce Formatting | Upgrade Parser | Manual Checkpoints |
|---|---|---|---|
| Candidate experience impact | High friction (candidates must learn rules) | Low friction (invisible to candidates) | No friction (review happens post-submission) |
| Annual cost estimate | Near zero | $3,000 to $15,000+ depending on volume | Staff hours only |
| Parsing accuracy gain | 85% to 95% for compliant resumes | 70% to 90% across all resume formats | 95%+ for reviewed candidates |
| Scalability | Scales with volume | Scales with volume | Breaks above ~50 applications per role |
| Candidate diversity risk | Penalizes non-standard backgrounds | Neutral | Neutral to positive |
| Time to implement | 1 to 2 weeks | 4 to 12 weeks | 1 to 3 days |
Who Should Pick Which
The pragmatic answer for most recruiting teams: you’ll need a combination, weighted differently based on hiring volume, role seniority, and how much candidate profile completeness matters for each position category.
High-volume teams hiring 15 or more roles simultaneously should lead with parser upgrades and layer in lightweight formatting guidance. A single line in your application instructions (“For best results, upload a .docx file with standard section headers”) captures the largest improvement in resume parsing accuracy without crushing candidate experience. That combination handles the 5,000-application months without requiring extra headcount.
Low-volume teams filling specialized or senior roles should invest in manual review checkpoints. The math works when you’re reviewing 20 to 50 candidates per role, and the cost of missing a qualified senior engineer or director-level hire dwarfs the five to eight hours of review per position.
Tip: Teams doing both high-volume and specialized hiring should split the approach by pipeline. Use enforced formatting plus upgraded parsing for hourly and entry-level roles, where volume demands automation. Add manual checkpoints for senior and hard-to-fill positions, where every candidate record deserves a human eye on the parsed data.
Building a structured hiring process that segments review depth by role type is the path that actually holds up under real recruiting workloads. It protects candidate profile completeness where it counts and keeps your team from burning 150 hours a month on data cleanup for roles where automation alone would have been good enough.