Switching from unstructured to structured interviews raises predictive hiring validity from .20 to .51, and adding behavioral anchors pushes that number to .57. Building the scorecard that makes this repeatable inside your ATS takes six steps, each under five minutes, producing a reusable candidate evaluation form that attaches to every interview on your team’s calendar.
TL;DR: Limit your scorecard to 6–8 weighted competencies, anchor every rating to an observable behavior, and build the template inside your ATS so it auto-attaches to calendar invites. Require interviewers to submit scores within 15 minutes of each interview. The build takes 30 minutes; the calibration session that makes it reliable takes 30 more.
The 87% of employers who now use skills-based practices at the interview stage already believe in structured evaluation. But only two-thirds of organizations actually follow through with a documented scoring process, according to current hiring research. That gap between intention and execution is where scorecards die. These six rules close it.
Cap your competencies at six to eight
Why does this range matter? Research on cognitive load during interviews shows that fewer than 5 competencies risks missing key job dimensions, while more than 8 dilutes interviewer focus and inflates evaluation time. The 6–8 range keeps your hiring rubric tight enough to score in real time and broad enough to cover what the role actually demands.
Start by pulling 3–4 competencies directly from the job description’s required qualifications. Add 2–3 competencies tied to the team’s working context: collaboration style, communication clarity, or domain-specific problem solving. If you’re weighing behavioral competency evaluation against skills testing, include at least one of each category so your scorecard captures both.
For a mid-level software engineer, your 7 competencies might be: technical problem-solving, system design reasoning, code quality standards, communication under ambiguity, collaboration with cross-functional teams, learning velocity, and alignment with team values. Every competency should map to at least one interview question. If you can’t write a question for it, cut it.
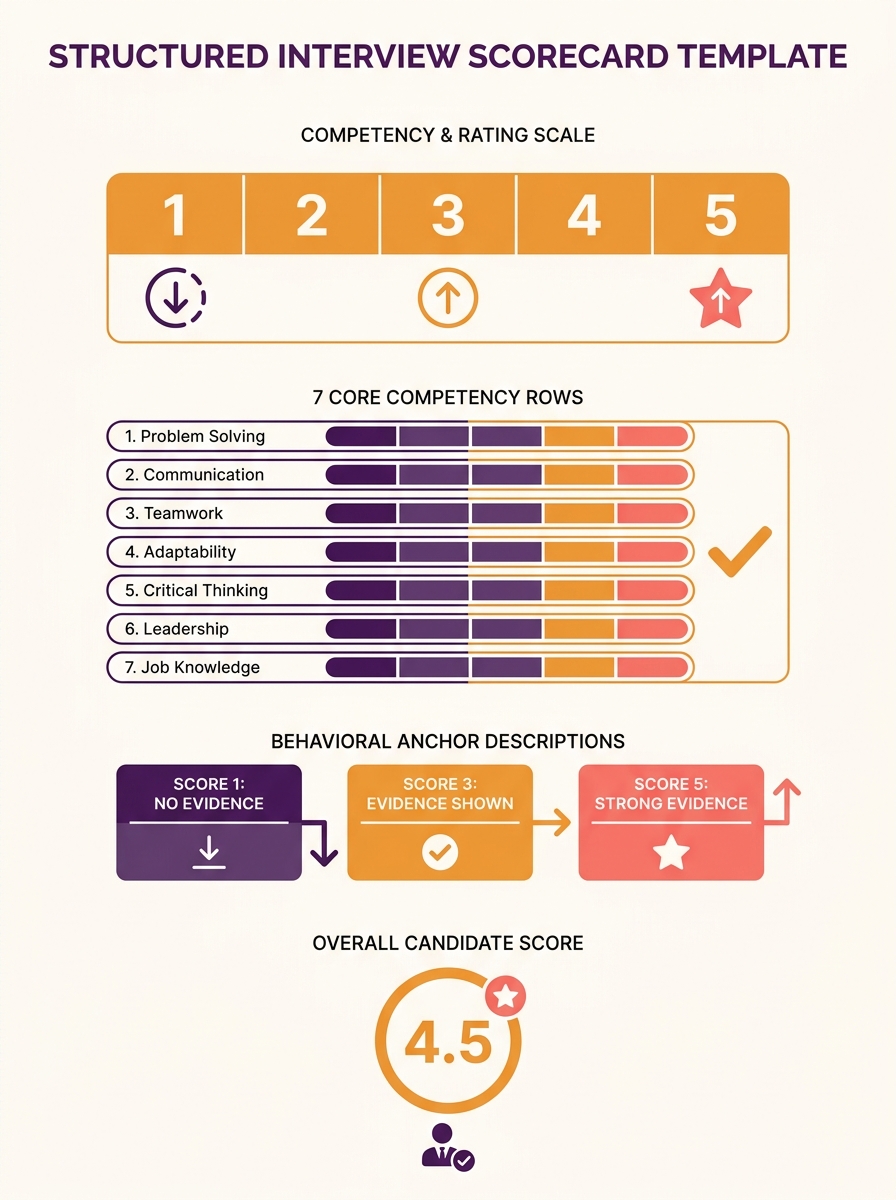
Anchor every score to a behavior you can observe
A 1–5 rating scale without behavioral anchors produces scores that cluster around 3 and 4, which tells you nothing. The fix is writing specific behavioral descriptions for at least three points on the scale: what a 1 looks like, what a 3 looks like, and what a 5 looks like.
As Juicebox’s 2026 rubric guide advises: “Make a point of discussing what a true ‘1’ looks like versus a ‘5.’ Remind them that a rubric isn’t about being nice; it’s about being accurate.” This framing is critical for building an equitable hiring process.
Here’s what anchored scoring looks like for a “communication under ambiguity” competency:
- Score 1: Candidate gave vague or circular answers when the question lacked a clear right answer. Could not articulate their reasoning process.
- Score 3: Candidate acknowledged uncertainty, offered a reasonable approach, and explained trade-offs with some prompting.
- Score 5: Candidate proactively named assumptions, structured their thinking aloud, and adjusted their approach when given new constraints.
If your team’s scores keep clustering in the middle even with anchors, switch to a 4-point forced-choice scale that eliminates the neutral midpoint entirely. This forces interviewers to commit to “below expectations” or “above expectations” on every dimension.

Weight the criteria before the first interview happens
Treating all competencies equally is a common scorecard mistake. A customer success manager role where communication accounts for 30% of daily work shouldn’t score communication the same as, say, spreadsheet proficiency. Assign percentage weights to each competency based on actual job demands before anyone conducts an interview.
A practical weighting split for that customer success role: client communication 30%, product knowledge 20%, problem resolution 20%, cross-team coordination 15%, documentation habits 15%. The total hits 100%. When you multiply each interviewer’s raw score by the weight, you get a final weighted score that reflects role priorities rather than interviewer preference.
If your ATS is designed for small and growing teams, check whether it supports weighted scoring natively. Workable’s built-in “Interview Kits” and scorecards, for example, embed structured hiring directly into the workflow so teams don’t need a separate spreadsheet for weight calculations. ATS interview templates that handle math automatically reduce both setup time and scoring errors.
Tip: Write your weights into the scorecard template itself so interviewers see them while scoring. Transparency about what matters most prevents 4 interviewers from each fixating on their personal favorite competency.
Build the template inside your ATS, not beside it
A scorecard in a Google Doc or a PDF attachment is a scorecard that 40% of your interviewers will forget to fill out. Building your structured interview scorecard directly inside your ATS solves three problems at once: it auto-populates candidate details, it attaches to calendar events, and it creates a centralized record that survives interviewer turnover.
ATS platforms with interview features can include rating criteria, interviewing instructions, sample questions, and a notes field linked to each scheduled interview. When the interviewer opens their calendar event, the scorecard is already there. No hunting through email for the right form. No version-control confusion.
If you’re evaluating platforms, look for these 4 ATS scorecard capabilities:
| Feature | Why It Matters | Fallback If Missing |
|---|---|---|
| Auto-populated candidate info | Eliminates manual data entry errors | Pre-fill a template with mail merge |
| Calendar-linked scorecards | 85%+ completion rates vs. ~60% for emailed forms | Send automated reminder 5 min post-interview |
| Weighted scoring calculations | Prevents manual math errors across 6–8 competencies | Use a formula in a shared spreadsheet |
| Score visibility controls | Prevents anchoring bias between interviewers | Require blind submission before debrief |
That last row matters more than most teams realize. If interviewer #2 can see interviewer #1’s scores before submitting their own, anchoring bias corrupts the data. Blind submission until all scores are in is a baseline requirement for any reliable candidate evaluation form. Many teams trying free recruitment software for the first time are surprised to find this feature already included.
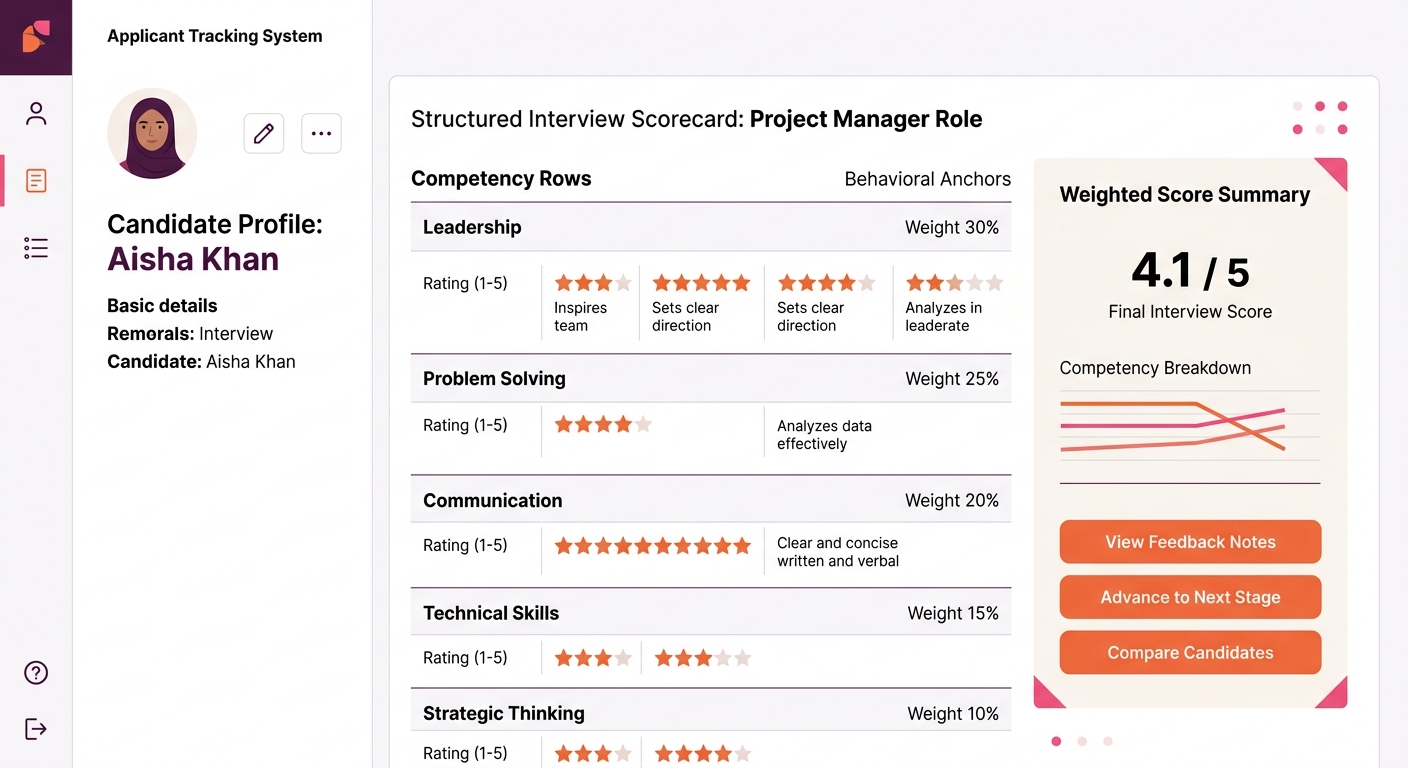
Run a 30-minute calibration before anyone interviews live
Interviewer calibration is where most scorecards succeed or fail. Two interviewers using the same hiring rubric can score the same candidate answer a 2 and a 4 if they haven’t aligned on what each level means. A single 30-minute calibration session before the interview loop begins eliminates most of that variance.
Metaview’s research on interview rubrics recommends a specific approach: “Run short training sessions, provide calibration exercises, and create quick reference guides that explain how to score consistently.” Even experienced interviewers interpret criteria differently without this alignment step.
Here’s a calibration session structure that fits in 30 minutes:
- Minutes 1–5: Walk through the scorecard. Read each competency and its behavioral anchors aloud.
- Minutes 6–15: Play a recorded mock interview (or read a transcript). Each interviewer scores independently.
- Minutes 16–25: Compare scores. Discuss every discrepancy of 2+ points. AIHR recommends you “discuss discrepancies openly to refine wording and reduce subjectivity” and track which anchors produce consistent scoring across raters.
- Minutes 26–30: Revise any anchor language that caused confusion. Lock the final version.
This exercise works best with 3 interviewers scoring 2 recent successful hires and 1 unsuccessful hire from historical data. The contrast between a known strong performer and a known poor fit sharpens everyone’s sense of the scale. If you’re tracking hiring outcomes through recruitment analytics, you already have the data to pick these calibration cases.
Two interviewers using the same hiring rubric can score the same candidate answer a 2 and a 4 if they haven’t aligned on what each level means.
Require scorecard submission within 15 minutes
Memory decay after an interview is steep. Research on post-interview evaluation timing shows that waiting even 30 minutes introduces recall bias, and waiting until the end of the day produces scores that reflect the interviewer’s mood more than the candidate’s answers. Set a hard deadline: 15 minutes post-interview, or the ATS flags the scorecard as overdue.
This rule has teeth only if the ATS enforces it. Configure automated notifications that trigger the moment an interview ends on the calendar. The notification should include a direct link to the pre-loaded scorecard, reducing submission friction to a single click. Completion rates jump from roughly 60% with emailed reminders to 85%+ with calendar-integrated, auto-triggered scorecard links.
One practical note on retention: completed scorecards should be stored for at least 1 year to withstand EEOC scrutiny. Federal contractors need to retain them for 2 years. Your ATS handles this automatically if scorecards live inside the system rather than in scattered documents.
When These Rules Break
These six rules assume a standard interview loop: 2–5 interviewers evaluating candidates for a single defined role. They bend or break in three scenarios.
Panel interviews with more than 5 evaluators. Score variance increases with panel size regardless of calibration quality. Above 5 interviewers, consider assigning each person only 2–3 competencies instead of the full set, then combining partial scorecards into a composite.
High-volume hourly hiring. When you’re filling 50 warehouse associate positions in 2 weeks, an 8-competency scorecard with behavioral anchors adds time you don’t have. Cut to 3–4 binary competencies (meets standard / does not meet standard) and skip the weighting. Speed matters more than granularity at this volume.
Executive-level roles. C-suite interviews involve strategic judgment and cultural influence that resist behavioral anchoring. You’ll still want a structured interview scorecard for the competency-based portions, but expect to supplement it with unstructured debrief notes on leadership presence and organizational fit. The scorecard provides the floor of rigor; it won’t capture everything.
The point of building this in 30 minutes is to remove the excuse that structured evaluation takes too long to set up. It doesn’t. The 72% reduction in hiring bias that structured interviews deliver depends entirely on whether the scorecard exists, lives inside your workflow, and gets filled out on time. These six rules make all three of those things happen by default.